
At Speechmatics, we wanted to present our real-time translation product in a straightforward yet impactful manner, demonstrating its exceptional capabilities. You can experience this firsthand on our website. Beyond its capabilities in showcasing real-time transcription and translation, our live demo extends its reach to address diverse user needs. For those who may have hearing impairments or find themselves in environments where audio isn't a viable option, our streaming server provides a text-based alternative, ensuring that no one is left out. Moreover, our service bridges language barriers, making it indispensable in situations where immediate translation is crucial, breaking down communication barriers effortlessly.
Overview of the Service
Our live demo offers a glimpse into the world of real-time transcription and translation, as it effortlessly handles live radio streams. Within this demo, users have the freedom to switch between four distinct live radio streams, each available in multiple target languages for translation.
To ensure the efficient utilization of our SaaS service, especially when accommodating potentially numerous concurrent visitors on our webpage, we embarked on the development of a backend streaming service. This service seamlessly manages the streaming of audio and translation results to our visitors while maintaining minimal reliance on our SaaS resources.
Furthermore, deploying this streaming service not only facilitates efficient resource allocation but also alleviates synchronization issues between audio playback and the corresponding translation results.
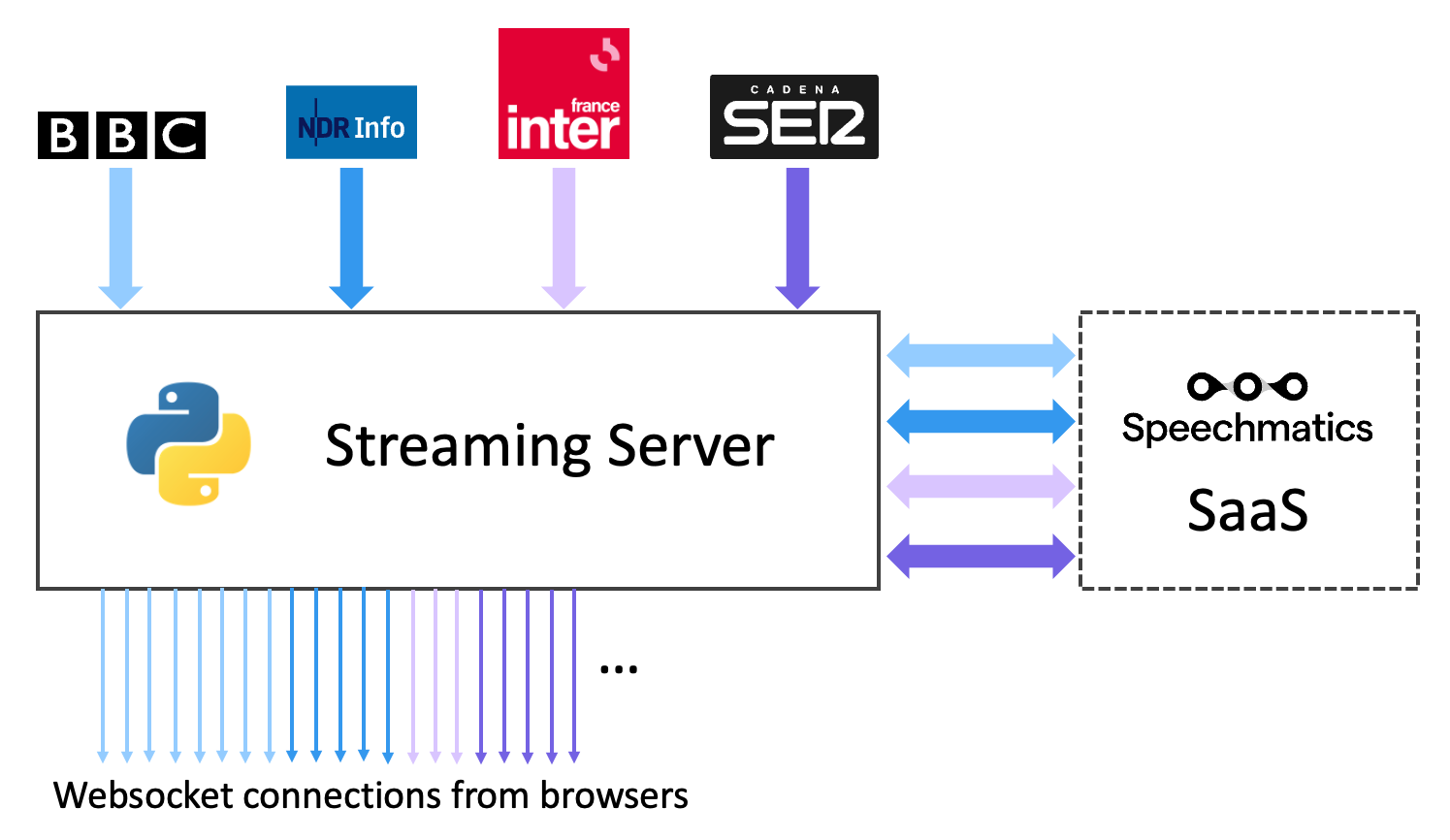
As depicted in the diagram above, despite serving a substantial number of WebSocket connections from web browsers, our streaming server efficiently manages just four audio streams and establishes four connections with our SaaS service.
The radio streams server code can be found in our Github repository.
Handling Websocket connections
To efficiently manage the influx of multiple incoming WebSocket connections, we harnessed the power of Python's asyncio library, which excels in handling IO-bound and high-level structured network code. When it came to WebSocket communication, we opted for the Websockets library, leveraging its default implementation built on top of asyncio.
For each incoming connection, our expectations are straightforward: we anticipate a single message requesting to "subscribe" to one of the four available radio streams. Once a connection has been established for an individual user, we proceed to store this connection in a dictionary, with the selected stream serving as the key. This approach enables us to construct a mapping between any given audio stream and all the connections that express an interest in receiving transcription and translation results for it.
Audio Stream Management
When a WebSocket connection requests access to a radio stream not currently in use, our system dynamically creates a new entry in the stream dictionary. The dictionary's value is an instance of a class named StreamState.
This specialized class serves as the custodian for all connections interested in the stream, alongside an essential internal asyncio task.
STREAMS[stream_name] = StreamState(
internal_task=asyncio.create_task(load_stream(stream_name)),
connections=[websocket],
)
The load_stream function , operating as an asyncio task, is responsible for the bulk of the work for the requested audio stream. Its core functionality is the following:
- Initiating an FFmpeg subprocess to capture audio from the live radio stream URL.
- Creating an instance of the Speechmatics Python SDK client for acquiring transcription and translation results specific to the stream's language.
- Launching an asyncio task that runs the configured Speechmatics Python SDK instance, utilizing the output of the FFmpeg subprocess as its audio source.
- Launching an asyncio task responsible for distributing audio chunks from the FFmpeg subprocess to all WebSocket connections subscribed to the stream.
To efficiently split the FFmpeg subprocess output into two distinct streams—one for feeding the Speechmatics Python SDK and the other for dispatching it to connected WebSocket clients—we employ a nifty Tee function.
This function writes data into two separate asyncio.StreamReader instances, ensuring the smooth flow of audio data to its intended recipients.
async def stream_tee(source, target, target_two, chunk_size):
while True:
data = await source.read(chunk_size)
if not data: # EOF
break
target.feed_data(data)
target_two.feed_data(data)
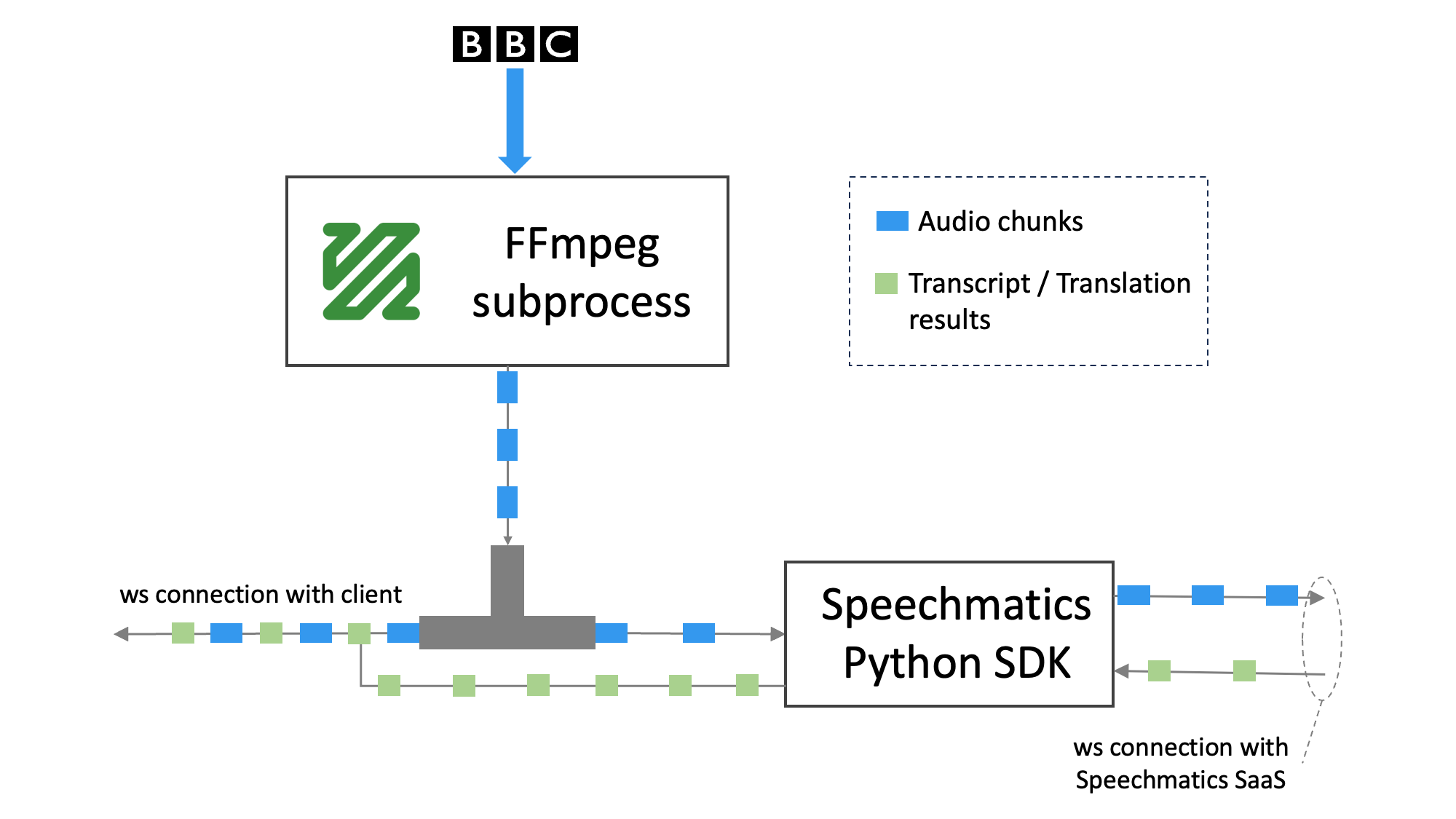
Making use of the Speechmatics Python SDK is the most convenient way of sending audio and obtaining transcription/translation results from our SaaS service.
To get started, we establish a configuration object that encapsulates our preferences, such as the translation target language, maximum delay, etc.
Subsequently, we create an instance of speechmatics.client.WebSocketClient and configure the callback functions for processing the different results.
Finally, we can execute it as an asynchronous task, utilizing one of the audio streams sourced from the FFmpeg tee as the audio input:
FRAME_RATE = 16000
FFMPEG_OUTPUT_FORMAT = "f32le"
ENCODING = f"pcm_{FFMPEG_OUTPUT_FORMAT}"
settings = AudioSettings(encoding=ENCODING, sample_rate=FRAME_RATE)
# Define the configuration including the optional 'translation_config' field
conf = TranscriptionConfig(
language=language,
operating_point="enhanced",
max_delay=3,
enable_partials=True,
translation_config=RTTranslationConfig(
target_languages=stream_meta.translation_languages, enable_partials=True
),
)
# Create an instance of the client
start_time = time.time()
sm_client = WebsocketClient(
ConnectionSettings(
url=url,
auth_token=AUTH_TOKEN,
)
)
# Configure the client to handle the different events that will be triggered
# when transcript/translation results arrive
sm_client.add_event_handler(
event_name=ServerMessageType.AddTranscript,
event_handler=partial(
send_transcript,
stream_name=stream_name,
start_time=start_time,
),
)
sm_client.add_event_handler(
event_name=ServerMessageType.AddPartialTranscript,
event_handler=partial(
send_transcript,
stream_name=stream_name,
start_time=start_time,
),
)
sm_client.add_event_handler(
event_name=ServerMessageType.AddTranslation,
event_handler=partial(
send_translation,
stream_name=stream_name,
start_time=start_time,
),
)
sm_client.add_event_handler(
event_name=ServerMessageType.AddPartialTranslation,
event_handler=partial(
send_translation,
stream_name=stream_name,
start_time=start_time,
),
)
sm_client.add_event_handler(
event_name=ServerMessageType.EndOfTranscript,
event_handler=partial(finish_session, stream_name=stream_name),
)
sm_client.add_event_handler(
event_name=ServerMessageType.RecognitionStarted,
event_handler=partial(receive_message, stream_name=stream_name),
)
sm_client.add_event_handler(
event_name=ServerMessageType.Error,
event_handler=partial(receive_message, stream_name=stream_name, level="error"),
)
sm_client.add_event_handler(
event_name=ServerMessageType.Warning,
event_handler=partial(
receive_message, stream_name=stream_name, level="warning"
),
)
sm_client.add_event_handler(
event_name=ServerMessageType.Info,
event_handler=partial(receive_message, stream_name=stream_name),
)
# Start running the client
asr_task = asyncio.create_task(sm_client.run(runtime_stream, conf, settings))
Monitoring with Prometheus Metrics
In addition to gathering essential metrics, such as CPU, memory, and bandwidth utilization, which can vary depending on how the app is deployed, we've also exposed two metrics that shed light on the state of our application:
- Number of WebSocket Clients Connected: This metric informs us about the current count of WebSocket clients actively connected to our server.
- Number of Streams Being Used: Here, the metric gets more granular by categorizing the open streams based on the language they represent. This provides valuable insights into which languages are currently in demand.
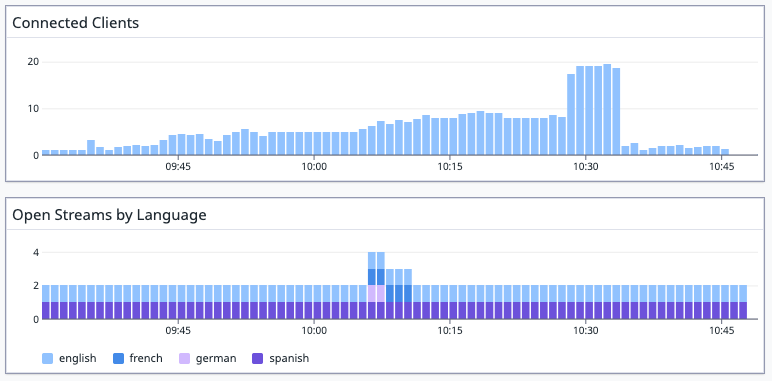
To make these metrics accessible and actionable, we've employed the Python Prometheus Client and exposed them as gauges. The "Number of Streams Being Used" metric takes advantage of language labels to offer a breakdown of open streams by language. Here's a glimpse of what these metrics look like in practice:
# HELP open_streams Amount of opened transcription/translation streams
# TYPE open_streams gauge
open_streams{language="english"} 1.0
open_streams{language="german"} 0.0
open_streams{language="spanish"} 0.0
open_streams{language="french"} 0.0
# HELP connected_clients Amount of clients connected to the ws server
# TYPE connected_clients gauge
connected_clients 3.0
It's worth noting that, due to the broadcast server's design, we shouldn't expect to observe more than one open stream for any given language at any given time.
After the metrics have been ingested by any metrics solution compatible with the open metrics exposition format, they can be used to create visualizations. Take, for instance, the examples below:
Profiling the application
Before deploying our application into a production environment, it was crucial for us to gain insight into the resource utilization of a single instance of the streaming server. We wanted to ensure its performance could meet the demands of real-world usage scenarios.
To achieve this, we used k6, a robust load testing tool. The beauty of k6 lies in its ability to effortlessly generate diverse load testing scenarios for WebSocket connections. We defined these scenarios in a concise and straightforward manner.
Consider the following load testing scenario as an example:
import ws from "k6/ws";
import { check } from "k6";
export const options = {
discardresponsebodies: true,
scenarios: {
users: {
executor: "ramping-vus",
startvus: 1,
stages: [
{ duration: "1m", target: 1 },
{ duration: "2m", target: 200 },
{ duration: "5m", target: 200 },
{ duration: "2m", target: 1 },
{ duration: "1m", target: 1 },
],
},
},
};
export default function () {
const url = "ws://127.0.0.1:8765";
const res = ws.connect(url, function (socket) {
socket.on("open", function open() {
console.log("connected");
const streams = ["english", "german", "french", "spanish"];
const random = Math.floor(Math.random() * streams.length);
socket.send(`{"name": "${streams[random]}"}`);
});
socket.on("close", () => console.log("disconnected"));
});
check(res, { "status is 101": (r) => r && r.status === 101 });
}
In this scenario, we begin with a one-minute stage where only a single client is connected. Subsequently, we ramp up to 200 connected clients over the course of two minutes. This load is sustained for five minutes before a gradual ramp-down over two minutes, bringing us back to just one connected client. Finally, we maintain this single client for the last minute.
During these load tests, we utilized memory-profiler to gain insights into the application's memory consumption. Here's the command we used to profile the application while it was under the described load test:
mprof run --multiprocess python3 -m stream_transcriber.server --port 8765
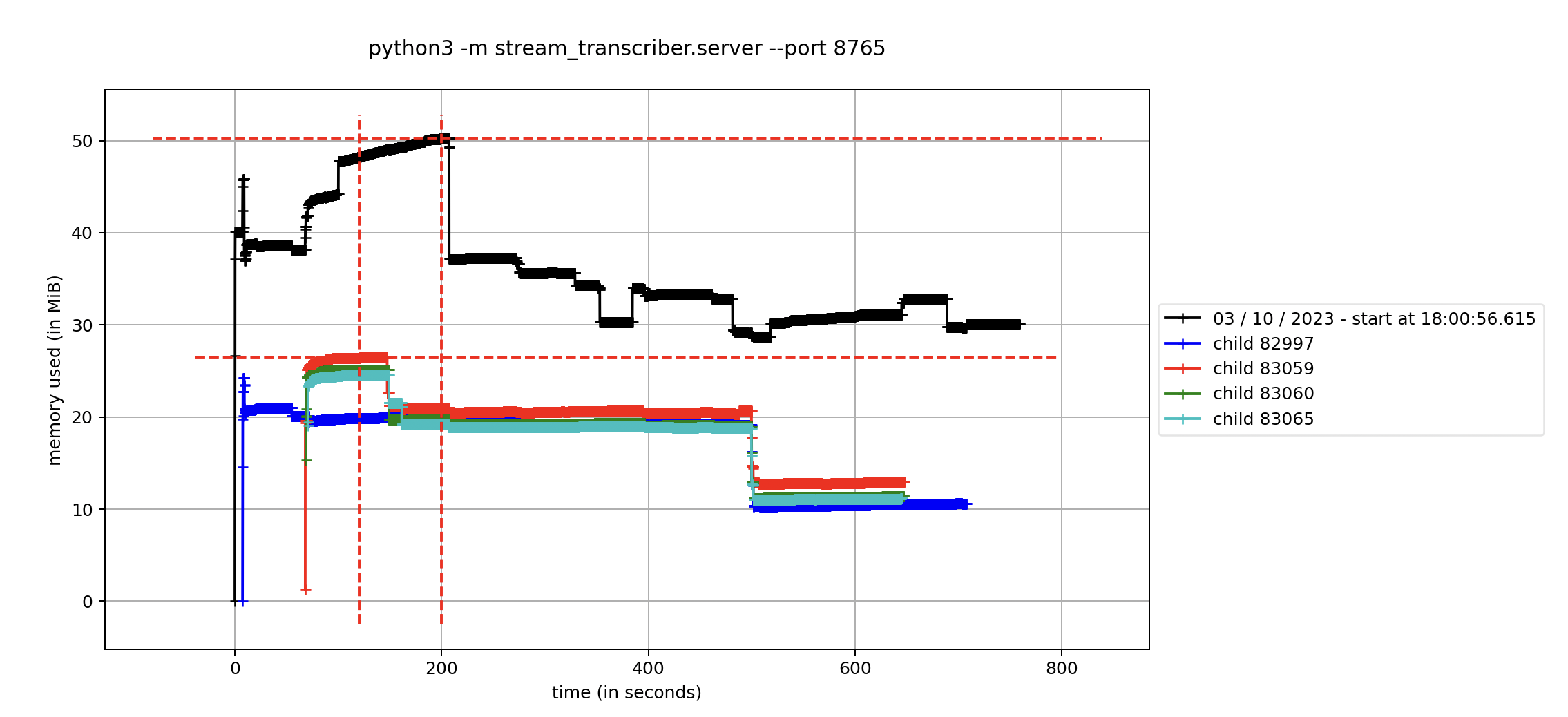
This memory profile allowed us to observe the memory usage of the Python streaming server and its various FFmpeg subprocesses. Notably, the Python server peaked at approximately 50 MiB while serving 200 users, and each FFmpeg subprocess consumed a maximum of around 27 MiB.
Furthermore, the execution of k6 provided us with valuable insights into network resource utilization, showcasing the data received by the 200 clients from the server during the test—amounting to 6.0 GB—and the rate at which it was received, which reached 8.7 MB/s.
data_received......: 6.0 GB 8.7 MB/s
data_sent..........: 89 kB 129 B/s
vus................: 1 min=1 max=200
vus_max............: 200 min=200 max=200
ws_connecting......: avg=1.32ms min=560.41µs med=1.28ms max=4.72ms p(90)=1.8ms p(95)=2.26ms
ws_msgs_received...: 3520595 5102.307069/s
ws_msgs_sent.......: 200 0.289855/s
ws_sessions........: 200 0.289855/s
This data is very useful when planning resource allocation for deploying radio stream instances. It helps us make informed decisions about how to effectively scale and optimize our application for real-world usage scenarios.
Conclusion
In this article, we've delved into the workings of our streaming radio translation server, including techniques for piping audio data using FFmpeg, harnessing the capabilities of Python's asyncio and Websockets library, as well as showcasing how we expose metrics and profile the application.
Before concluding, we invite you to explore our Python Radio Streams Server and SDK further. You can find the code for the Radio Streams Server on our Github repository. The Python SDK can be found in it’s own Github repository. We encourage you to get hands-on, experiment, and contribute to our project. Your feedback and insights are highly appreciated as we continue to refine and enhance our streaming solution.