

As Transformer models increase in size, the computational cost of running inference also grows. Many organisations now face the challenge of deploying state-of-the-art models in a cost-effective way.
One popular technique for doing so is quantization - by reducing the numerical precision of network parameters and activations, quantization aims to increase throughput and decrease memory footprint.
Of course, this is less useful if quantizing to lower precision harms model accuracy. The first part of this blog introduces the quantization formulation, and explores techniques for minimising such degradations.
Reducing peak memory usage by quantizing from FP16 to INT8 is pretty much guaranteed. However, achieving throughput improvements is more difficult. The main challenge stems from overheads associated with the quantization/dequantization operations, which can mask performance gains from the blazingly fast INT8 Tensor Core matrix multiplies. The second part of this blog explores the nuances around achieving peak performance on GPU.
Contents
- Part I: Accurate Quantization
- Part II: Fast GPU Quantization in Practice
- Part III: FP8 & The Future of 8-bit Quantization
- References
Part I: Accurate Quantization
Background Concepts
We'll start with a brief overview of quantization theory. This is not intended to be an exhaustive explanation; rather, it will serve as context for subsequent sections. For a more in-depth explanation, we recommend the blogs and papers given in the References section [1-4].
The Quantization Equation
In principle, we can use any function to convert from a higher-precision to lower-precision representation. But a linear function is simplest and quickest [4]:
Here, and are the fixed-point output and floating-point input, while and represent the scale factor and bias. is a function that rounds to the nearest integer, clipping values outside of the representable range:
After applying our lower-precision operation we return the data to its original dynamic range with dequantization:
This method is called uniform quantization since the quantized values are uniformly distributed over the input space. To calculate we select a clipping range and then use:
Here, is the number of bits in our quantization scheme. GPU based quantization schemes typically enforce , which is known as symmetric quantization. This simplifies the (de)quantization functions by setting fn1, which helps reduce the cost of the transformation [4].
It's important to note that the rounding function in Equation incurs a loss of information. In general, . The value is called quantization error.
Dynamic vs Static Quantization
A key question is how to determine the clipping range - determined by . Too small, and we'll excessively “truncate” outlier activations and weights. Too big, and we'll lose precision.
While model parameters can always be quantized ahead of time, its activations can either be quantized dynamically (with the clipping range calculated for each activation during a forward pass) or statically (also offline).
Dynamic quantization tends to be more accurate but requires additional computational overhead for online scalar calibration. As a result, we only consider static quantization on GPU because the scalar reduction (relative to an INT8 matmul) can be costly and limit performance gains.
Calibration
Static quantization involves obtaining activation quantization parameters by passing several batches of data through the model to measure activation distribution. This process is called calibration.
There are multiple methods to derive a clipping range from these activations, such as:
- Taking the min/max value from the calibration data
- Taking some percentile (e.g 99.99%) to determine the max value
- Minimising KL Divergence between the input and quantized distributions
- Minimising the Mean-Squared Error between input and quantized distributions
The following figure [5] shows a histogram of input activations for some layer in a neural network. The vertical lines represent the maximum clipping range, , for various calibration schemes:
![]()
To perform calibration, one option is TensorRT's PyTorch Quantization Toolkit. Another is to use the QuantStub and DeQuantStub nodes from PyTorch directly, to capture the relevant statistics.
Quantization Granularity
A final distinction to be made is how quantization parameters are shared between elements of our parameters and activations. Consider the following diagram of a matrix multiplication:

The simplest approach is to use the same scale factor for all elements of (and likewise for ). This is known as per-tensor quantization.
It's also common to share quantization parameters between some subgroups of each input matrix. A popular option is to assign a specific scale factor to each column of , referred to as per-channel (or per-column) quantization. This is more accurate than per-tensor quantization; using a specific scale means the error incurred in quantizing each column is lower.
Specifics of INT8 GEMMs
The core element of a quantized neural network is INT8 matrix multiplication. Understanding its details is crucial for an efficient implementation. This section describes these details, and serves as context for Part II.
We identify two types of INT8 matmul, differentiated by their return type.
I8I32
Consider the following matrix multiplication:
where , , are the input, weight, and output tensors respectively. We omit a bias for simplicity. Consider the case where and are FP16, but the matrix multiply runs in INT8. An INT8 in INT32 out (I8I32) matrix multiplication is implemented as follows:
 1-cef832a9957f3b5dd3b81d92351f0e65.svg)
The arrows indicate a data transfer with dtype given by their colour. The square boxes indicate operations, with dtype of the return variable also given by their colour.
There are several points to note:
- The input first passes through a quantization operation, labelled Q. This performs the operation described in Equation .
- Our weights can be quantized offline.
- The accumulated output of the Matmul has INT32 dtype. This is because multiplication of two signed INT8 values can be represented in INT16. Since a matmul involves the addition of several INT16 values, the accumulator must have dtype INT32 to prevent overflow.fn2
- The output is passed through a dequantization op, labelled DQ. This performs the operation described in Equation , and returns in FP16.
I8I8
Returning in INT8 involves an extra step:

In this requantization step, labelled RQ, we convert the INT32 representation back into INT8. The benefit is a reduction in the amount of data written from GPU SRAM to DRAM - and so higher performance.
We can think of requantization as first dequantizing to a floating point value, , and subsequently quantizing. The requantization scale factor combines these steps:
where , , and are the scale factors associated with the input, weights, and intermediate variable .
Quantization Operation Overheads
To fully realise throughput improvements from INT8 matrix multiplications, we must reduce the cost of the Q/DQ/RQ nodes. Since these are element-wise operations, this can be achieved through operator fusion [6]. The following diagrams demonstrate this for I8I32 and I8I8. Fused operators are indicated by the dashed boxes:
-fa94021692d397adff8d4638b74b8449.svg)
-fce858b2631bb581aa9749e43e502bbe.svg)
In both cases, the Q node can sometimes be fused with a preceding operation, in this case a layernorm. In I8I32, we see the DQ is fused with the matrix multiply itself. This ensures the dtype of the tensor that's transferred between SRAM and DRAM is FP16 instead of INT32. In I8I8, we see the RQ is fused with the matmul. This ensures an INT8 return type. The DQ can sometimes be fused with following ops (for example, a residual add).
For more detail, see the section on Operator Fusion Implementation.
Quantization-Aware Training
So far, we have explored Post-Training Quantization, in which model weights are converted to INT8 after training. The degree of accuracy degradation depends upon the effectiveness of our calibration methods.
Another approach, Quantization-Aware Training, accounts for the impact of quantization during the training process. It can be viewed as a fine-tuning stage, adjusting model parameters to better adapt to quantization effects, thereby minimizing accuracy degradation.
Specifically, we insert nodes into the computational graph that do quantization, followed immediately by dequantization. These are labeled "QDQ" in the following diagram:

Inserting QDQ nodes in this manner is exactly equivalent to doing a quantized matrix multiply, such as the one illustrated in the I8I32 section.
We insert QDQ nodes for every quantized matmul in our network. Note that the above diagram represents I8I32 quantization. To prepare for I8I8, we insert an additional QDQ node after the matrix multiply to emulate the requantization step.
The process is then relatively straightforward: we calibrate each QDQ node, and subsequently fine-tune the model parameters. However, there is a complication related to back propagation: the quantization operation is non-differentiable. In practice, we simply ignore this issue by treating the derivative of each QDQ node as the identity function. This assumption is referred to as the Straight-Through Estimator.fn3
Alternatives to QAT
For situations where QAT is insufficient or undesirable, other approaches can be considered.
Recent research paper LLM.int8() [7] highlighted the existence of extreme outliers in large language models, which severely degrades accuracy when quantizing to INT8. Their solution was to decompose each matrix multiplication into 8-bit and 16-bit parts, where the wider ranged FP16 was used to preserve outliers.
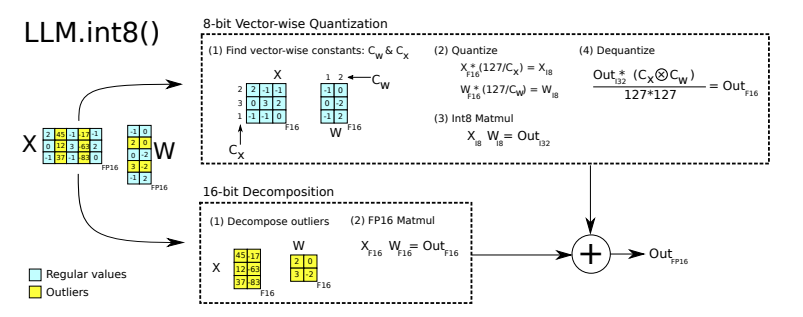
This yielded promising results, but also introduced a performance overhead so is most useful for reducing peak memory.
Another paper that we found to give practical benefits was SmoothQuant [8]. They again focus on the effect of outliers but importantly, SmoothQuant can be applied offline, meaning there is no performance overhead when running inference.
The authors describe two key observations that motivate their approach:
- The distribution of neural network weights is uniform and flat. The distributions of activations is not. This makes activations harder to quantize than weights.
- Activation outliers appear in fixed channels.
The following diagram, taken from the original paper, illustrates these ideas for a single linear layer:
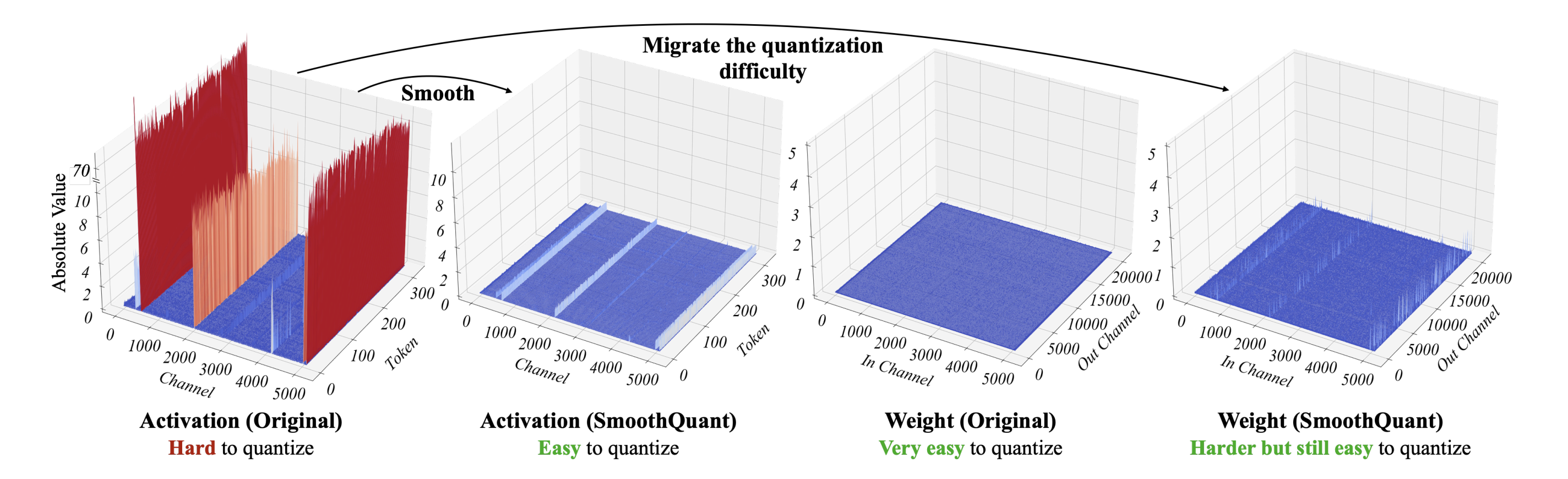
On the left-hand side, we see dramatic outlier channels in the input tensor. Given this, an obvious solution would be to apply a per-channel quantization factor. Unfortunately, this is not feasible: applying a scaling factor to individual columns of the input tensor would not factor out nicely in the output, meaning we could not apply dequantization.
Other works have instead used a per-token quantization granularity. This can improve accuracy slightly, but does not solve the issue of fixed-channel outlier values.
Instead, SmoothQuant aims to "migrate" the quantization difficulty from activations to weights. It does so by scaling each channel of the activations by a "smoothing factor". To ensure mathematical equivalence, we must scale each token of the weight tensor by the same amount in the opposite direction.
Mathematically, this is given by:
where is our smoothing factor. Here's a diagram, again taken from the paper:
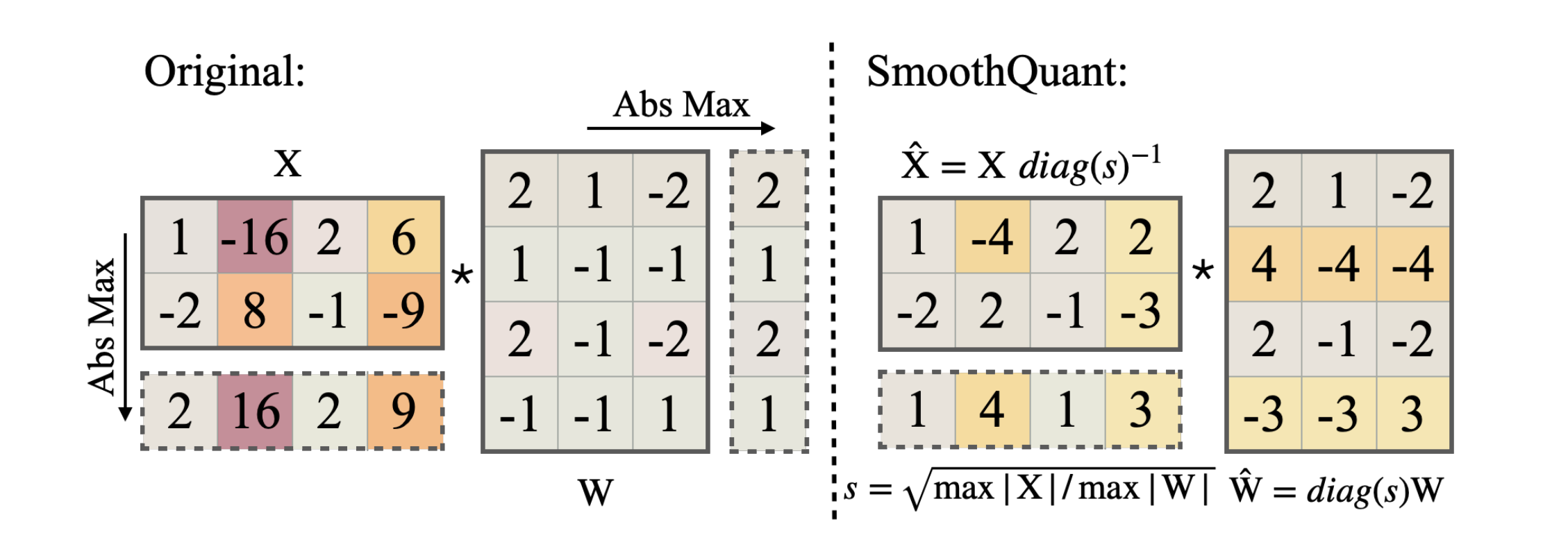
All that remains is how to determine . Since quantization is easiest when all channels have the same maximum value, one possibility is:
where is the channel index. This ensures that all channels would have the same maximum value (of 1). However, this may push too much of the quantization difficulty to the weights, meaning we harm quantization accuracy.
The other extreme is:
To control the migration strength, the authors propose combining each of these equations by introducing a hyperparameter, :
corresponds to migrating all difficulty to the weights. migrates all difficulty to the activations. In general, setting to be between 0.5 and 0.9 achieves good performance.
It's important to reiterate that this smoothing process can be applied offline. For the weights, this is trivial. For the activations, we exploit the fact that GEMM operations in a transformer block often follow a layernorm. Combining the multiplication by into the layernorm parameters means that it too can be done offline.
A consequence of this is that SmoothQuant can only be applied (without performance overhead) to matrix multiplications that follow an operation which can accommodate a smoothing factor into its parameters, such as LayerNorm. The diagram below indicates the relevant matrix multiplies in a standard transformer block:
![]()
Part II: Fast GPU Quantization in Practice
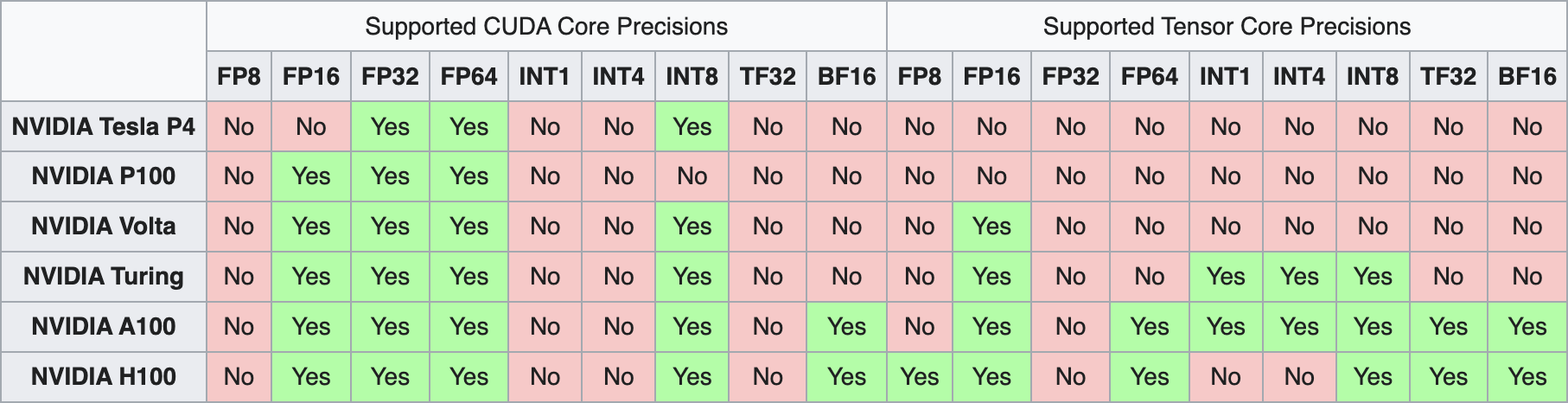
In order to run INT8 GEMMs efficiently on CUDA GPUs we must execute the operation against INT8 Tensor Cores. These were first introduced with the Turing architecture (compute capability 7.0+). INT4 and INT1 Tensor Cores also exist but have been deprecated in future architectures (see the figure below, taken from Wikipedia). We therefore focus on INT8 quantization.
Executing against Tensor Cores can be achieved by running the mma.sync.aligned.m8n32k16.row.col.s32.s8.s8.s32 PTX instruction, or calling wmma::mma_sync at the CUDA level. However, both approaches require careful management of data movement and layouts to maximize Tensor Core throughput.
Thankfully, these lower level details are abstracted away by the cuBLASLt cublasLtMatmul and CUTLASS device::Gemm APIs, both of which support IMMA (integer matrix multiply accumulate).
Available Solutions
While integration with these APIs is currently not supported natively in PyTorch, there are other libraries available such as torch-int (SmoothQuant [8]) and bitsandbytes (LLM.int8() [7]) which expose Python bindings to the underlying cuBLASLt/CUTLASS calls. Microsoft's ZeroQuant [9] also leverage CUTLASS, but wrappers for their INT8 kernels are not open source.
Although these libraries offer flexibility and easy integration, they don't currently provide performance gains and are consistently slower than FP16. This is due to prioritizing accuracy and memory savings or lacking efficient quantization implementations.
In contrast, fully-fledged inference frameworks such as TensorRT (TRT) and FasterTransformer do achieve performance gains. They also manage the complexity of fusing quant & dequant nodes with adjacent operators. This is appealing for common Transformer types such as BERT and GPT, for which they have been heavily optimised. However, the rigid assumptions made by these libraries make them less suitable for more unusual architectures.
Specifically, whilst TRT supports generic ONNX models, to achieve peak performance in their BERT implementation they rewrite the model using the TRT Network Definition API, and utilize custom plugins (such as fused multi-headed attention). This level of manual intervention means the benefits of a more generic model export + inference runtime are diminished. FasterTransformer's INT8 compatible models have been rewritten in C++ in order to leverage the best performance by using the non-standard interleaved data layout required by cuBLASLt. This limits the extensibility of existing INT8 model implementations for novel architectures.
Ideally, we can achieve the performance of these inference frameworks while retaining the flexibility of torch-int and bitsandbytes. The remainder of this blog concentrates on achieving both good INT8 performance and flexibility.
Memory Layouts
As previously suggested, ensuring that input and weight matrices satisfy specific memory layout requirements is essential for INT8 GEMM performance. By default, all PyTorch operators expect a row-major ordering for input and outputs tensors. Ideally, we'd use the same layout for our INT8 matmul to avoid conversion overhead.
Unfortunately, this is not the case with cuBLASLt which operates on column major by default. The cublasLtMatmul API does support a row major input tensor with column major weight tensor (and we can transpose the weight tensor offline), but the output is returned in column major. In other words, input/weight/output = ROW/COL/COL. CUTLASS goes further and supports ROW/COL/ROW out of the box, which makes it a great option for PyTorch integrations.
While these options are already faster than FP16, performance can be further improved by using the COL32/CUBLASLT_ORDER_COL32_2R_4R4/COL32 layout for input tensors. This layout is very non-standard but can significantly boost performance.
COL32 is an interleaved layout which can be interpreted as row-major ordered but in blocks of 32 columns. CUTLASS supports this by specifying cutlass::layout::ColumnMajorInterleaved<32>. CUBLASLT_ORDER_COL32_2R_4R4 is even more exotic and is best explained visually.
The diagrams below depict 32x64 matrices where each numerical value represents the memory address offset for that element.
Row major (CUBLASLT_ORDER_ROW)

Column major (CUBLASLT_ORDER_COL)
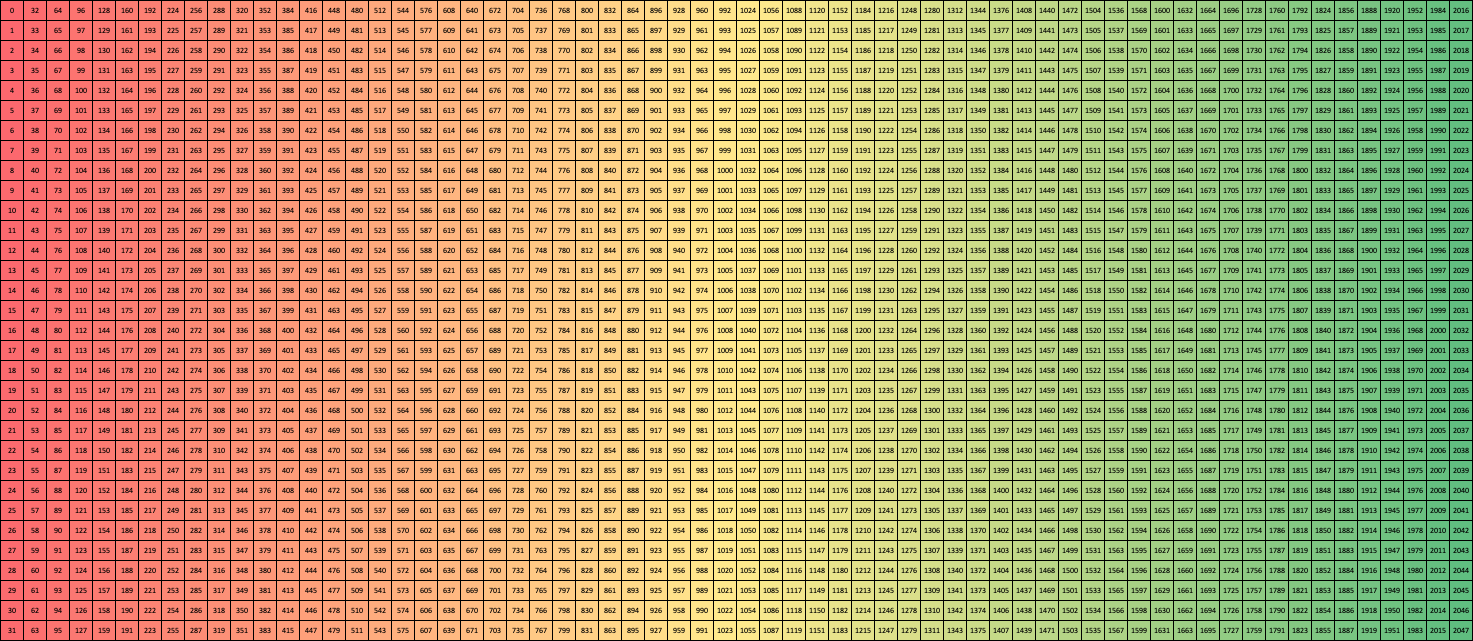
Column 32 (CUBLASLT_ORDER_COL32)
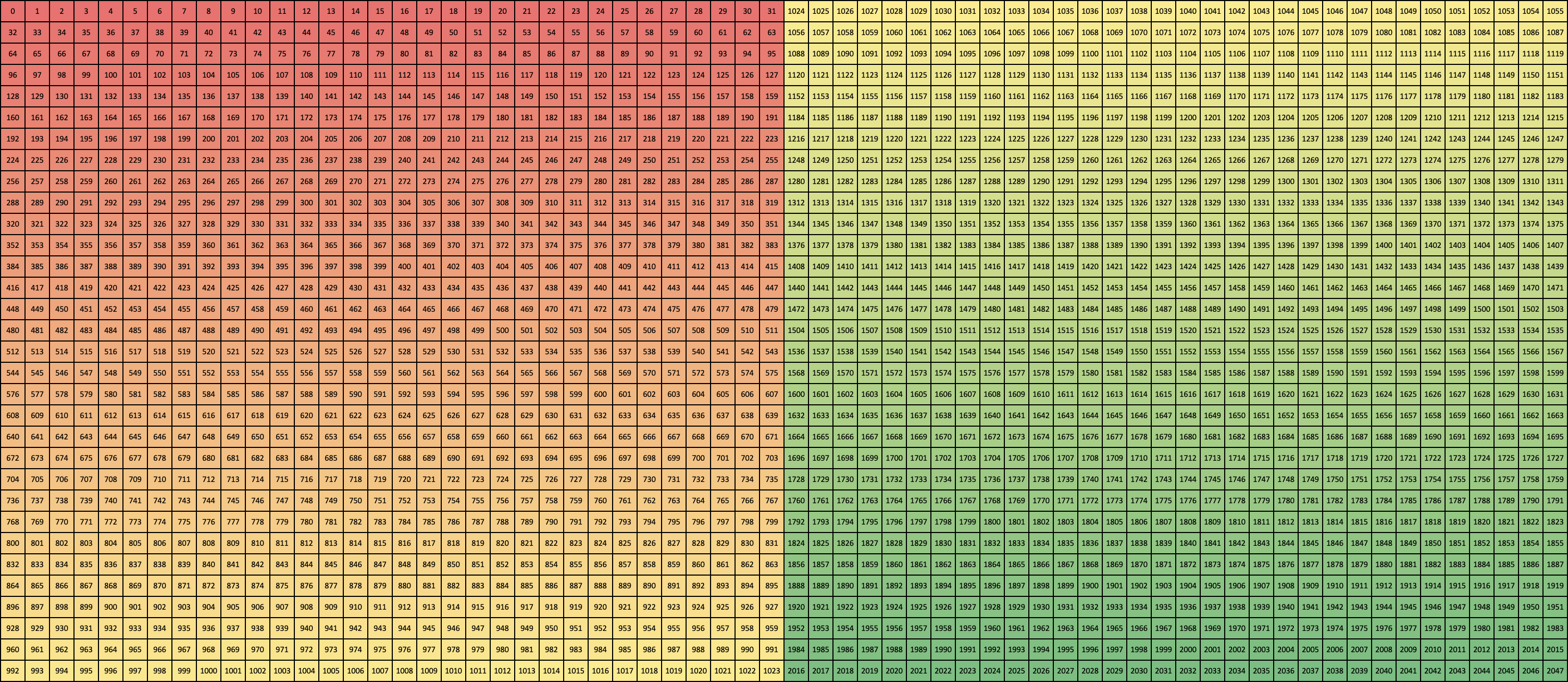
Column Turing (CUBLASLT_ORDER_COL4_4R2_8C)
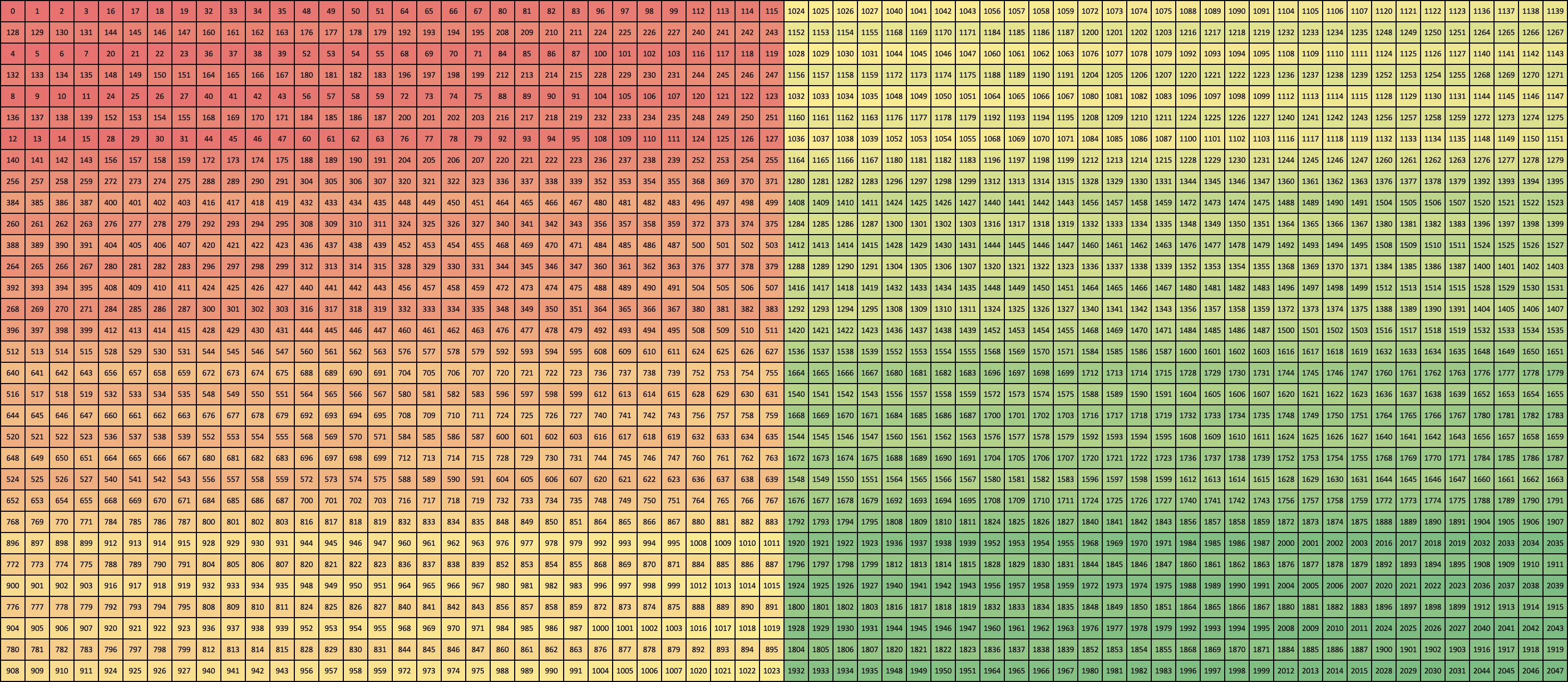
Column Ampere (CUBLASLT_ORDER_COL32_2R_4R4)
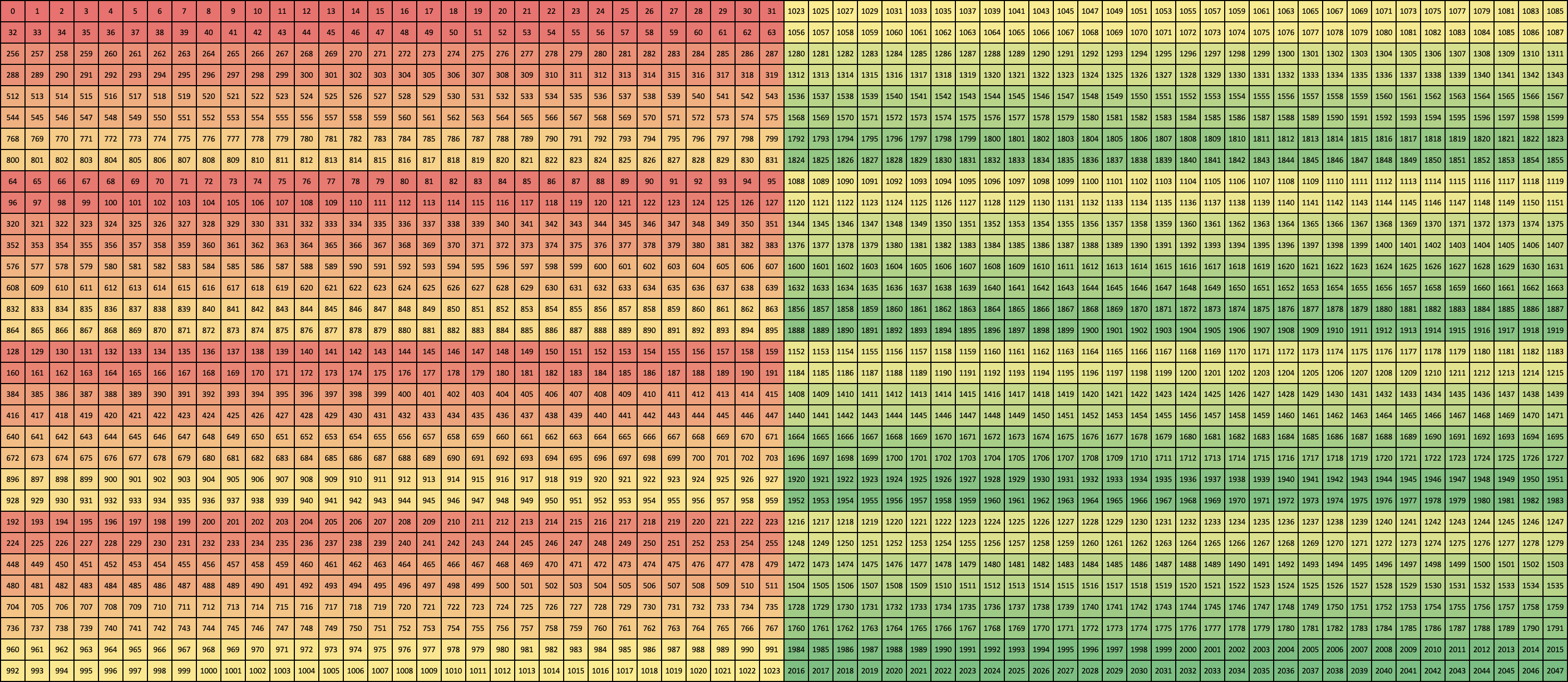
Zooming in on the first 16 x 4 elements gives a clearer picture of the layout pattern:
Row major (CUBLASLT_ORDER_ROW)

Column major (CUBLASLT_ORDER_COL)

Column 32 (CUBLASLT_ORDER_COL32)

Column Turing (CUBLASLT_ORDER_COL4_4R2_8C)

Column Ampere (CUBLASLT_ORDER_COL32_2R_4R4)

While COL32 is the most performant layout, it comes with an associated cost of layout conversion. This may cancel out any gains from the reduced precision matmul. Therefore, we must decide to either:
- Persist the data in the required format (à la Faster Transformer).
- Hide the cost via kernel fusion.
The latter approach is similar to how quantization/dequantization overhead is typically hidden, which is discussed next.
Operator Fusion Implementation
As described in the Quantization Operation Overheads section, kernel fusion is essential to developing a quantized model with superior throughput to FP16. To avoid the pain of writing CUDA, these can be implemented using OpenAI's Triton Language[10]. This section provides a short example.
Consider the code below. It demonstrates a modified Layernorm kernel, based upon that given in the Triton documentation. Besides performing the layernorm operation, it also:
- Fuses a quantization op,
_quant(), and - Converts data layout from row-major to COL32 (see
cols_out).
"""
Example Triton kernel that implements fused Layenorm + Quantization.
Also performs layout conversion from row-major to COL32.
The kernel code is adapted from the Triton Lang tutorial.
See https://triton-lang.org/main/getting-started/tutorials/05-layer-norm.html
"""
import triton
import triton.language as tl
@triton.jit
def layernorm_Q(
Input,
Output,
Weight,
Bias,
quant_scale,
stride, # Stride between rows
M, # Number of rows
N, # Number of columns
eps: tl.constexpr,
BLOCK_SIZE: tl.constexpr,
):
stride_out = 32 # Because COL32
# Position of elements processed by this program
row = tl.program_id(0)
Output += row * stride_out
Input += row * stride
# Layenorm: Compute mean
mean = 0
_mean = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
cols = off + tl.arange(0, BLOCK_SIZE)
a = tl.load(Input + cols, mask=cols < N, other=0.0, eviction_policy="evict_last").to(tl.float32)
_mean += a
mean = tl.sum(_mean, axis=0) / N
# Layernorm: Compute variance
_var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
cols = off + tl.arange(0, BLOCK_SIZE)
a = tl.load(Input + cols, mask=cols < N, other=0.0, eviction_policy="evict_last").to(tl.float32)
a = tl.where(cols < N, a - mean, 0.0)
_var += a * a
var = tl.sum(_var, axis=0) / N
rstd = 1 / tl.sqrt(var + eps)
# Layernorm: Multiply by weight, and add bias
cols = off + tl.arange(0, BLOCK_SIZE)
mask = cols < N
weight = tl.load(Weight + cols, mask=mask)
bias = tl.load(Bias + cols, mask=mask)
a = tl.load(Input + cols, mask=mask, other=0.0, eviction_policy="evict_first").to(tl.float32)
a_hat = (a - mean) * rstd
y = a_hat * weight + bias
# Quantize
pos_clamps = tl.zeros([BLOCK_SIZE], dtype=tl.float32) + 127
neg_clamps = tl.zeros([BLOCK_SIZE], dtype=tl.float32) - 127
y = (y * quant_scale).to(tl.float32)
y = tl.libdevice.rint(y)
y = tl.where(y > 127, pos_clamps, y)
out = tl.where(y < -127, neg_clamps, y)
# Pointer arithmetic for Row-major --> COL32
cols_out = cols // stride_out * (stride_out * M) + (cols % stride_out)
# Store output
tl.store(Output + cols_out, out, mask=mask)
INT8 GEMM Benchmarking
We now examine performance numbers for various flavours of INT8 GEMM. For these benchmarks, we wrap the C++ APIs for cuBLASLt and CUTLASS as PyTorch extensions.
Benchmarks were run on a T4 GPU with input tensors of shape [2048, 1920] and [1920, 1920]. While mileage may vary for different input shapes, the following conclusions were found to be consistent over a variety of shapes/sizes.
For a detailed guide to timing CUDA kernels with PyTorch, see this previous blog.
INT8 vs INT32 output precision
One important factor which determines INT8 GEMM performance (formula above) is the return type. The matrix multiplication will always have INT8 dtype for matrices and , which then accumulate in INT32 within the kernel. But we need to decide whether output should be INT8 or INT32.
INT32 return type will be slower as four times as much data is written out (and read into the next kernel).
In comparison, INT8 return type is faster but there is a trade-off: accuracy will be worse, as we need to requantize the output from INT32 to INT8 within the kernel. More information on this can be found in earlier sections.
The measured throughput figures are shown below:
| Kernel | Time (ms) | vs. FP16 |
|---|---|---|
| F16F16 (Torch) | 600 | 1.0x |
| I8I32 (cuBLASLt) | 364 | 1.65x |
| I8I8 (cuBLASLt) | 308 | 1.95x |
Overall, the decision is very much dependent on the accuracy/performance trade-off, as well as the specifics of the model architecture.
FP16 output precision
We previously touched upon the fact that INT32 return type requires dequantizing outside of the matmul. Performance can be improved by fusing the dequant with the matmul itself, and returning FP16 outputs.
We can achieve this for free by using the GEMM α parameter to dequantize the outputs (the same way that we requantize INT8 outputs). However, this only works if we apply per-tensor quantization, where the dequantization parameter is a single scalar.
What if we require per-channel quantization? In this case, CUTLASS comes to the rescue by allowing the definition of a custom epilogue function, which loads the vector based scalar. This is applied after the matrix multiplication, in a single fused kernel. The GEMM + epilogue definition is expanded to:
The epilogue format comes from EpilogueWithBroadcast which applies a binary operationf1 between the matmul output and a column-wise broadcasted vector d, followed by an optional element-wise op f2.
f1 might typically be a bias addition followed by an activation function (e.g. ReLU) for in f2. In our case we want f1 to be a multiplication with the dequantization scalar and f2 to be the identity. The epilogue is then plugged into gemm::device::GemmUniversalWithBroadcast.
| Kernel | Time (ms) | vs. FP16 |
|---|---|---|
| F16F16 (Torch) | 600 | 1.0x |
| I8I32 (CUTLASS) | 461 | 1.30x |
| I8F16 (CUTLASS) | 438 | 1.37x |
Whilst there might not be huge throughput improvements from FP16 output for the matmul itself, there are other performance benefits to the next kernel in the sequence (following the matmul):
- 50% less data loaded (now FP16 instead of INT32)
- Avoid fusion requirement with the dequantize operator (simpler)
- Avoid loading the dequantization vector (CUTLASS hides the cost of this load by pipelining it with the matmul computation)
Memory layout
Lastly, we examine the effect of memory layout on matmul performance:
| Kernel | Time (ms) | vs. FP16 |
|---|---|---|
| F16F16 Row major (Torch) | 600 | 1.0x |
| I8I8 Row major (cuBLASLt) | 365 | 1.64x |
| I8I8 COL32 (cuBLASLt) | 308 | 1.95x |
As expected, COL32 is most performant.
Part III: FP8 & The Future of 8-bit Quantization
The arrival of Nvidia's Hopper/Lovelace architectures brings support for a new floating point datatype - FP8. This is available in two formats:
- E5M2 - 5 exponent bits and 2 mantissa bits - larger dynamic range
- E4M3 - 4 exponent bits and 3 mantissa bits - higher precision
Choosing an FP8 quantization format can have both accuracy and performance benefits.
Data Distribution Alignment
When quantizing from FP16 to INT8, we not only reduce the range and number of values that can be represented, but also change the underlying distribution. Most of the tensors we want to quantize will be normally distributed. This mirrors the representable floating point values - and is in contrast to the fixed point integers which provides a uniform distribution. Research already suggests that we can remove/reduce the need for QAT by using FP8 over INT8 [11],[12].
The image below illustrates the distribution of representable values for INT8 (top) and FP8 (bottom). These have been scaled to have the same min/max.

FP8 Training
Quantization-Aware Training results in decreased training throughput, and approximate gradients (due to the Straight-Through Estimator). In contrast, FP8 tensor cores combined with libraries like Transformer Engine pave the way for accurate and performant 8-bit training.
cuBLASLt API
Although FP8 tensor cores have the same theoretical throughput as INT8, changes to the cublasLtMatmul API for FP8 means we can avoid a lot of the pain associated with achieving peak 8-bit performance. Specifically:
- Input requires Row Major memory layout rather than COL32 - so we can bypass this conversion overhead
- The GEMM API now accepts additional scalars which are multiplied with the input/output tensors. This can be used to fuse quantize/dequantize with the matmul itself.
Both of these changes mean we can consider each matmul in isolation, without having to apply fusions with adjacents operations.
References
- Subramanian, Suraj, et al. "Practical Quantization in PyTorch" (2022).
- Mao, Lei. "Quantization for Neural Networks" (2020).
- PyTorch Docs - Quantization.
- Gholami, Amir, et al. "A survey of quantization methods for efficient neural network inference." arXiv preprint arXiv:2103.13630 (2021).
- Wu, Hao, et al. "Integer quantization for deep learning inference: Principles and empirical evaluation." arXiv preprint arXiv:2004.09602 (2020).
- He, Horace. "Making Deep Learning Go Brrrr From First Principles" (2022).
- Dettmers, Tim, et al. "Llm. int8 (): 8-bit matrix multiplication for transformers at scale." arXiv preprint arXiv:2208.07339 (2022).
- Xiao, Guangxuan, et al. "Smoothquant: Accurate and efficient post-training quantization for large language models." arXiv preprint arXiv:2211.10438 (2022).
- Yao, Zhewei, et al. "ZeroQuant: Efficient and affordable post-training quantization for large-scale transformers." Advances in Neural Information Processing Systems 35 (2022): 27168-27183.
- Tillet, Philippe, Hsiang-Tsung Kung, and David Cox. "Triton: an intermediate language and compiler for tiled neural network computations." Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages (2019).
- Kuzmin, Andrey, et al. "FP8 Quantization: The Power of the Exponent." arXiv preprint arXiv:2208.09225 (2022).
- Micikevicius, Paulius, et al. "FP8 formats for deep learning." arXiv preprint arXiv:2209.05433 (2022).
- The idea that setting implies that is non-trivial. It holds true because we enforce two conditions for our quantization scheme: the first is that and map to the maximum and minimum values of our quantized representation respectively, for instance and in INT8; the second is that . For more detail, see Lei Mao's blog [2].↩
- It's still theoretically possible to encounter an overflow if a large number of INT16 values are added together. However, this is unlikely in practice and the use of an INT32 accumulator is sufficient.↩
- Since the Straight-Through Estimator totally ignores each QDQ node, the TensorRT PyTorch Quantization docs choose not to use the term "Quantization-Aware Training". They argue that "if anything, it makes training being 'unaware' of quantization".↩