
Imagine being able to understand and interpret spoken language not only retrospectively, but as it happens. This isn't just a pipe dream — it's a reality we're crafting at Speechmatics.
Our mission is to deliver Speech Intelligence for the AI era, leveraging foundational speech technology and cutting-edge AI.
In 2023, we launched a series of Capabilities that look to do more with the spoken word. Moving beyond transcription, we're now offering powerful functionality that interprets, analyses and makes the spoken word more useful and valuable than ever before. So far, we've released Translation, Summaries, Sentiment, Chapters and Topics, but our journey has only just begun.
Having these Capabilities work for batch transcription is great (that is, sending us a media file after it has been recorded), but we also understand that in many situations, retrospective analysis of audio files isn't fast enough. Our users need something that can deliver value whilst the conversation or audio is being created. In other words, in real time.
Imagine a call center supervisor needing instant feedback on the sentiments of all the calls happening at any given moment, so they can step in to assist with calls where a customer is deeply unhappy and the agent needs a helping hand from someone more senior. Having sentiment in batch simply can't keep up in this scenario. This is where Real-Time Capabilities become not just beneficial but essential.
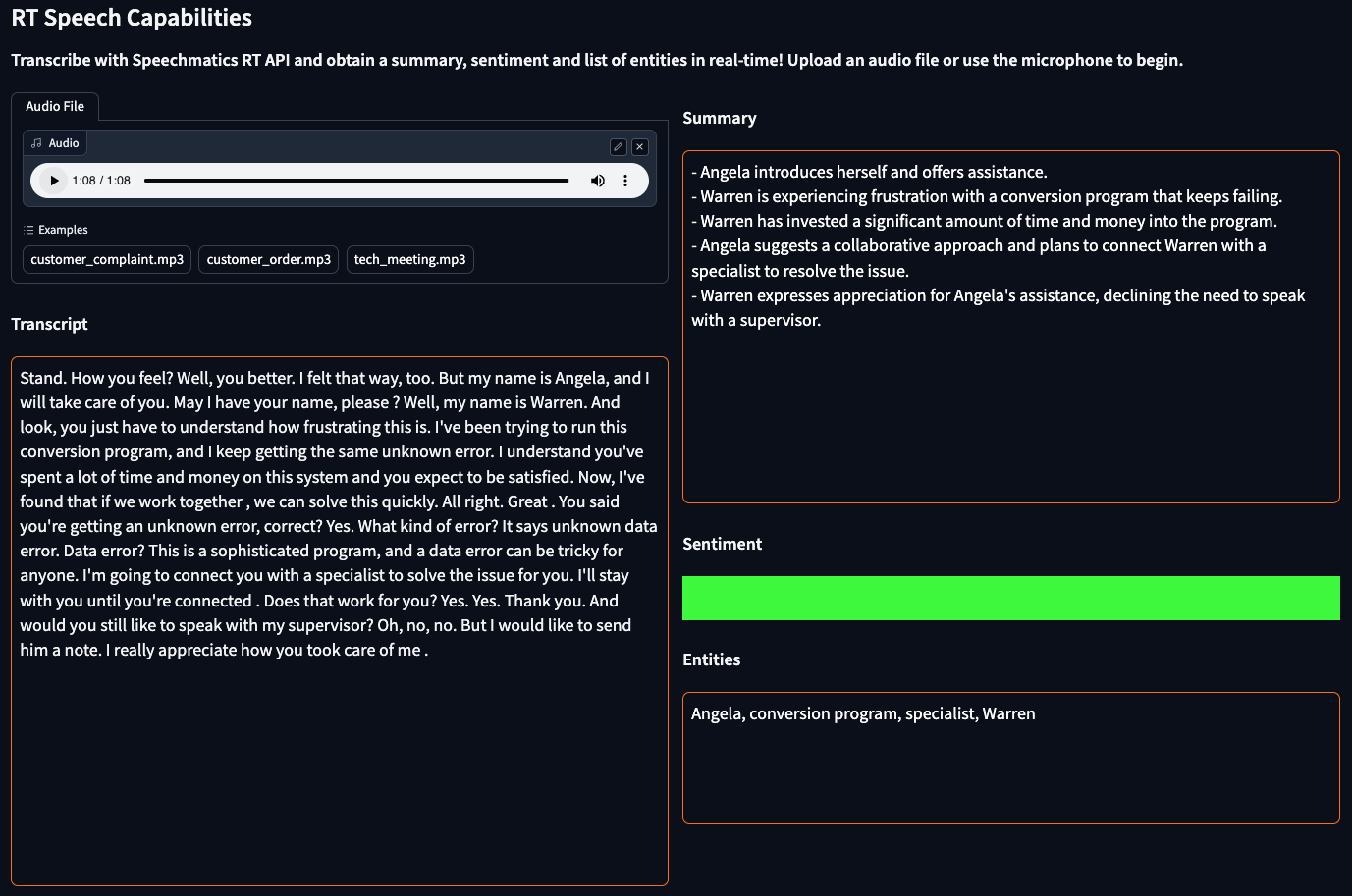
To showcase the potential of Real-Time Capabilities, I've developed a demo, which we have also released as a video for The.Shed.
In this article, I'll take you behind the scenes, and walk you through how we can easily build such a demo by using Speechmatics RT API and OpenAI's ChatCompletion API.
Building the demo with Gradio
To build this demo, I'll be using Gradio, an open-source Python framework. Gradio simplifies creating intuitive UIs around complex machine learning models, perfect for quick sharing and testing.
First, we can define the layout of the application in a few lines of Python using Gradio's Blocks API. To upload an audio file to be streamed, we can simply import a gr.Audio component. Key thing to take note here is how we define the callbacks to 1) transcribe when the audio component streams, and 2) have the HTML components watch the changes and display the transcription and relevant capabilities (summary, sentiment, entities) in real-time.
with gr.Blocks(title="RT Capabilities") as demo:
with gr.Row():
with gr.Column():
with gr.Tab("Audio File"):
file_audio = gr.Audio(source="upload", type="filepath", format="mp3")
gr.Markdown("### Transcript")
transcript_box = gr.HTML(value=transcript)
with gr.Column():
gr.Markdown("### Summary")
summary_box = gr.HTML(value=summary)
gr.Markdown("### Sentiment")
sentiment_box = gr.HTML(value=sentiment)
gr.Markdown("### Entities")
entities_box = gr.HTML(value=entities)
# Call `transcribe_file` when the file streams
file_audio.play(transcribe_file, inputs=[file_audio], preprocess=False)
# Watch for changes in transcript and call summarize
transcript_box.change(display_transcript, inputs=None, outputs=[transcript_box], every=1)
summary_box.change(display_response, inputs=None, outputs=[summary_box, sentiment_box, entities_box], every=1)
# Clear outputs before running file
file_audio.change(clear_responses)
Integrating with Speechmatics Python SDK
To transcribe in real-time, we make use of the Speechmatics Python SDK, the most convenient way of sending an audio stream and obtaining transcription results from our SaaS service. To get started, we create an instance of speechmatics.client.WebSocketClient, with the default connection settings.
SM_WS_CLIENT = speechmatics.client.WebsocketClient(
speechmatics.models.ConnectionSettings(
url="wss://eu2.rt.speechmatics.com/v2",
auth_token=os.environ["SM_API_KEY"],
)
)
Subsequently, we can configure the callback functions to process and store both the partials and finals.
def update_transcript(msg):
global transcript
current_transcript = msg["metadata"]["transcript"].strip()
if len(current_transcript) > 0:
transcript += current_transcript + " "
def update_partial(msg):
global partial_transcript
partial_transcript = msg["metadata"]["transcript"].strip()
SM_WS_CLIENT.add_event_handler(speechmatics.models.ServerMessageType.AddTranscript, event_handler=update_transcript)
SM_WS_CLIENT.add_event_handler(speechmatics.models.ServerMessageType.AddPartialTranscript, event_handler=update_partial)
With the Speechmatics Client created, we can now define the transcribe_file callback as an asynchronous task, using the stream from the audio component as the input. Additional configuration for AudioSettings and TranscriptionConfig can be found here. In order to read the audio file at native frame rate (i.e. simulate a live stream), we will need a DelayedRealtimeStream wrapper to pipe the audio through FFmpeg. The implementation of the wrapper can be found in the full working example which I'll link at the end of the article.
SM_SETTINGS = speechmatics.models.AudioSettings(
sample_rate=48000,
chunk_size=1024,
encoding="pcm_s16le",
)
SM_CONFIG = speechmatics.models.TranscriptionConfig(
language="en",
operating_point="enhanced",
max_delay=5,
enable_partials=True,
enable_entities=True,
)
async def transcribe_file(filepath_obj):
filepath = filepath_obj["name"]
factory = partial(get_audio_stream_proc, filepath=filepath)
with DelayedRealtimeStream(factory) as audio_source:
await SM_WS_CLIENT.run(audio_source, SM_CONFIG, SM_SETTINGS)
Using OpenAI API to extract relevant insights
Once we obtain the transcription in real-time, we can apply Natural Language Processing techniques to process the transcript to produce a summary and detect sentiment and key entities. While this step might have been a complex task a year ago, the explosive rise of LLMs and its rapid democratization have made this step as simple as calling another API. The easiest way to extract insights from the transcript would be to use OpenAI's ChatCompletion API.
As seen in the method below, we can use the ChatCompletion API with some simple prompting to process the transcript and extract the relevant insights. The key thing to take note here is how often we want the summary, sentiment and entities to be updated, which we configure with MIN_CONTEXT_WORDS.
MIN_CONTEXT_WORDS = 20
OPENAI_CLIENT = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
async def call_chat_api(prompt):
response = await OPENAI_CLIENT.chat.completions.create(
messages=[{"role": "user", "content": prompt}],
model="gpt-4-1106-preview",
max_tokens=300
)
return response.choices[0].message.content
async def get_capabilities():
return await asyncio.gather(
call_chat_api(SUMMARY_PROMPT.format(text=transcript)),
call_chat_api(SENTIMENT_PROMPT.format(text=transcript)),
call_chat_api(ENTITIES_PROMPT.format(text=transcript)),
)
def get_response():
global transcript
global prev_transcript
global summary
global sentiment
global entities
# Calculate difference in length between latest transcript and previous transcript
new_context_len = len(transcript.split()) - len(prev_transcript.split())
# Only call the OpenAI API if the difference is more than MIN_CONTEXT_WORDS
if new_context_len > MIN_CONTEXT_WORDS:
prev_transcript = transcript
summary, sentiment, entities = asyncio.run(get_capabilities())
return summary, sentiment, entities
That's it!
Using the above, you have now got a complete demo where you can see the live transcription, and alongside it a dynamic summary that updates as the call progresses, as well as a sentiment indicator, and a summary of the identified entities.
Considerations for real world applications
Of course, the above is only a demo - it serves as a proof-of-concept that could be used to show to customers to test their appetite for such a feature (as an API company ourselves, we understand the need to create compelling demos of our product outside of showing off our code). Assuming the response from these customers was positive, you could then move this into your roadmap, where you'd need to think about creating a general release version of this.
There are many other factors to consider moving from a demo like this to a consistent and reliable production-grade feature. Here are some key questions:
- If we use LLM APIs as our tool-of-choice, how do we ensure the low latency of the responses and uptime reliability?
- How do we address indeterminism and “hallucinations” coming from LLM responses?
- How do we efficiently handle lengthy transcripts as the transcript becomes longer and longer for long audio streams?
- Are we missing out on audio cues (e.g. tone, pitch, laughter) by only using the text transcript to detect sentiment?
These are the key challenges that the engineers at Speechmatics have been working on when developing Real-Time Capabilities. We're sharing this because we know that our users and customers are hungry for innovation and have talented teams of their own - we suspect a few will not want to wait and will work on creating production ready features sooner rather than later.
Real-time innovation - over to you.
In this article, we've explored how Gradio, Speechmatics RT API, and OpenAI's ChatCompletion API can be combined to create a powerful demo of Real-Time Capabilities. While this post covers the fundamentals, the full working example is available on our Github repository. For more in-depth information, our technical documentation offers extensive guidance on how to integrate Speechmatics APIs into your applications.
We're excited about the potential of our technology and eager to see what you can achieve with it. If you've built something innovative using Speechmatics API, or if you have any questions, feel free to reach out to us on Twitter/X, GitHub, or LinkedIn. We're not just here to answer questions; we're looking for collaborators and innovators who share our vision for the future of Speech Intelligence.