
Complete this sentence: "I love lamb..." What comes next? "it pairs so well with mint", or "it's perfect in a Sunday roast?" What if the conversation has been about poetry, in which case this probably refers to Charles Lambe, and the phrase could continue "his poetry is so moving". If the preceding conversation had been about the movie Anchorman, it may have been "I love lamp".
The important difference between these scenarios is the context.
By changing the context each time, the interpretation of the word is shifted. The more context you have, the more likely you can interpret it correctly. With any information channel, the more context which can be delivered the better. When I speak to another person, I carry with me a huge amount of contextual information about who they are, what our relationship is, my goals, their goals, and the context for why we are interacting (and even visual cues). Humans also do not always immediately understand every word spoken, and can update their understanding as more words are spoken, to fill in gaps, or differenciate similar words.
But what happens if you cannot change the context and can only view that first phrase? For example, in the case of live captioning the words have to be delivered as soon as they are spoken. This is the challenge of real time transcription. The results are needed as fast as possible, without losing the accuracy of transcription. This is the subject of this blog - how do we balance speed and accuracy in real time transcription?
The source of latency in ASR
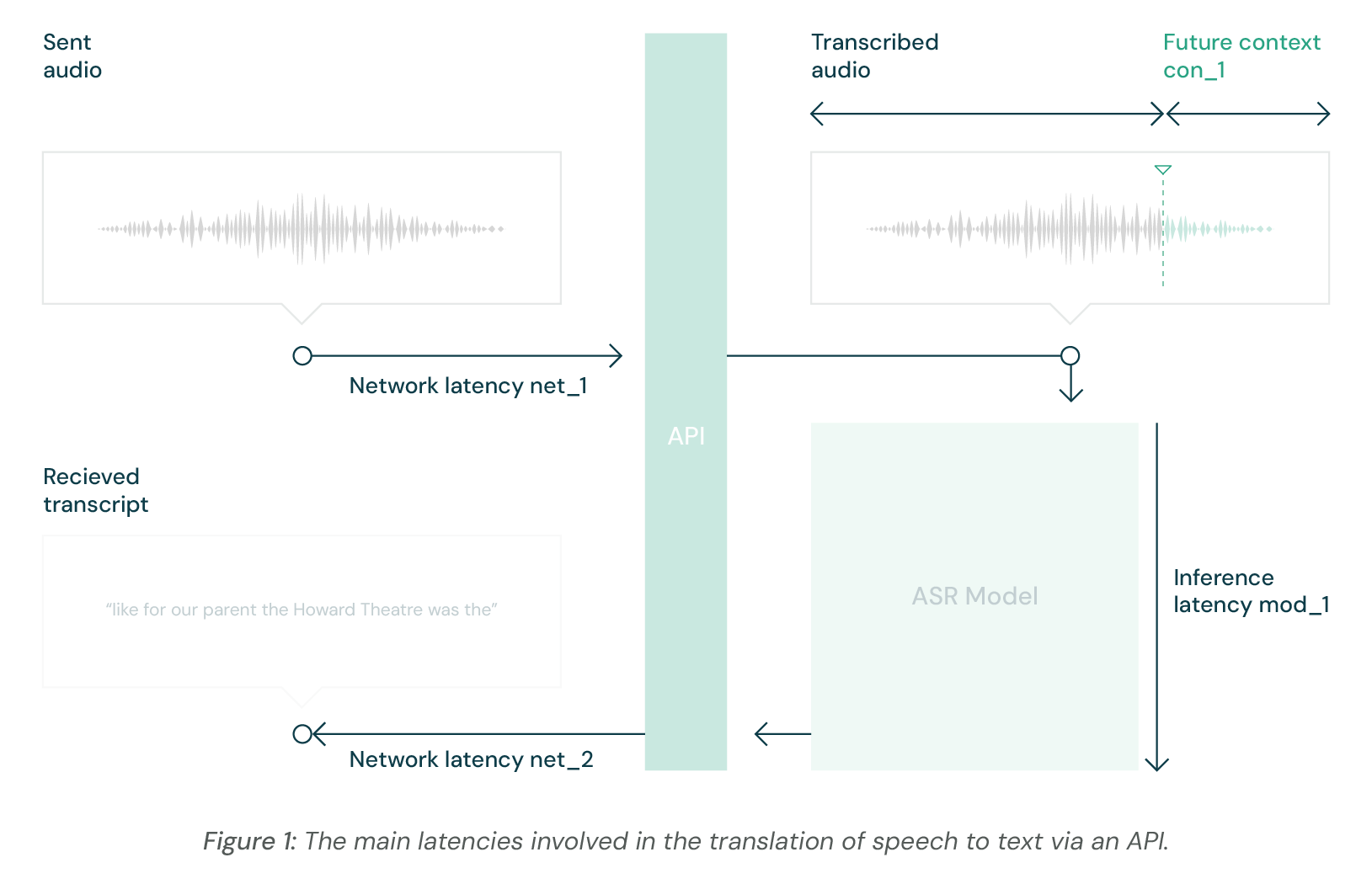
Figure 1 shows some of the main sources of latency associated with an ASR service. There are two main portions of the latency seen by the end user of a speech transcription service. There are infrastructure delays (net_1+net_2+mod_1) and there are information delays (con_1). The infrastructure delays can be mitigated with on-premises compute or a better host for the model, for example, but are not the subject of this analysis. The information delays are used to make the transcriptions better, exchanging latency for accuracy by ensuring all words transcribed have both past context (what has already been said) and future context (the sounds and words coming after).
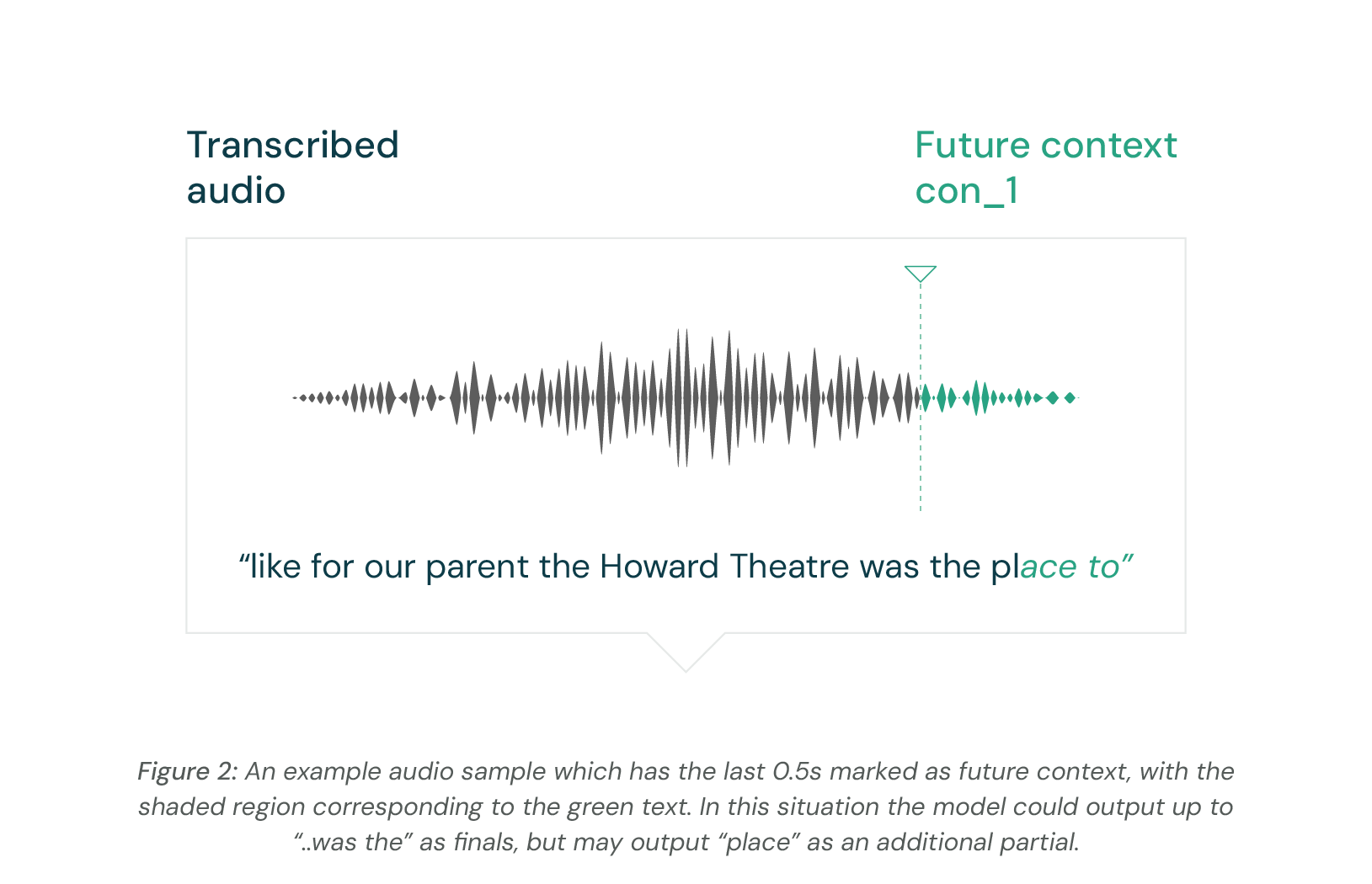
In example in Figure 2, the full audio sent ends with “was the place to”. The model may output “... Theatre was the". The word “to” may be the start of a longer word like “totally” and more context is needed to know for sure. The word “place” is completely seen by the model but will have low certainty due to the lack of future context. However, this best guess at the word “place” can be used to give context to the words “was the”.
This gives us the final returned transcript, where we have reasonable confidence in all the returned words. Many ASR providers will return two messages in this situation, the “final” ending in “...was the”, and the “partial” (a lower confidence message) including “...was the place”.
This is a simple demonstration of what context means for a model. If you have played with an ASR API you will see that the partials often update over time as more context is received.
With this in mind, let's start exploring how to measure the accuracy of real time transcription
Measuring real-time accuracy
If the goal of your real-time system was just to get the lowest latency possible, you could try to predict the words during or in advance of vocalisation. This could get you low, and even negative, latencies. However, these predictions are likely to be poor given the lack of acoustic signal.
The goal is to characterize the transcription accuracy of a system for a given latency. Two conceptual decisions were made in developing this metric:
1) We are interested in the accuracy of the words when they first appear. If a word is initially incorrect and is later corrected, it still counts as an error as we may already have acted on the incorrect transcription.
2) We want to characterize the real latency experienced by the end user of a system. It is interesting to understand where this comes from, but an API user does not care whether the latency comes from model inference or model context. We therefore take the full latency between verbalization of the word, and the return of the transcript.
The first step is to take a given ASR test set and force align it. This is a process through which a transcript and an audio file can be combined in order to get the start and end timings of the vocalisation of each word. Using our internal tools, we can align words with an average precision of ~30ms, which will also therefore serve as the floor on the resolution of these metrics.
The latency of the transcript is based on the force aligned word end time. We simply take the average length of time between the time the word first appeared in the transcript to when it finished being vocalised:
Note that we only use words which were correctly transcribed for the timing metric. The accuracy considers all words, and is the word error rate (WER). For partials, we take the words as they first appear, knitting together a transcript from the new words received at each partial.

Figure 3 shows an example of a typical set of messages received while transcribing a simple audio file. Several partials arrive before a final is received. Figure 4 shows how these messages are knitted together, with each word timestamped.

If we assume the final transcript is correct, the only error seen is the return of the word “exam” instead of “example” in the case of the partials, due to the model not seeing the real end of the word. The average time for the partials will be much lower however, due to the words being returned as they appear, as opposed to the sentence chunks of the finals.
Results
We now discuss the results of applying the real time accuracy/latency metrics to real models. Figure 5 shows a latency-accuracy curve produced by varying the max_delay parameter in a Speechmatics model. This parameter forces the model to return with no more than the given amount of audio context.
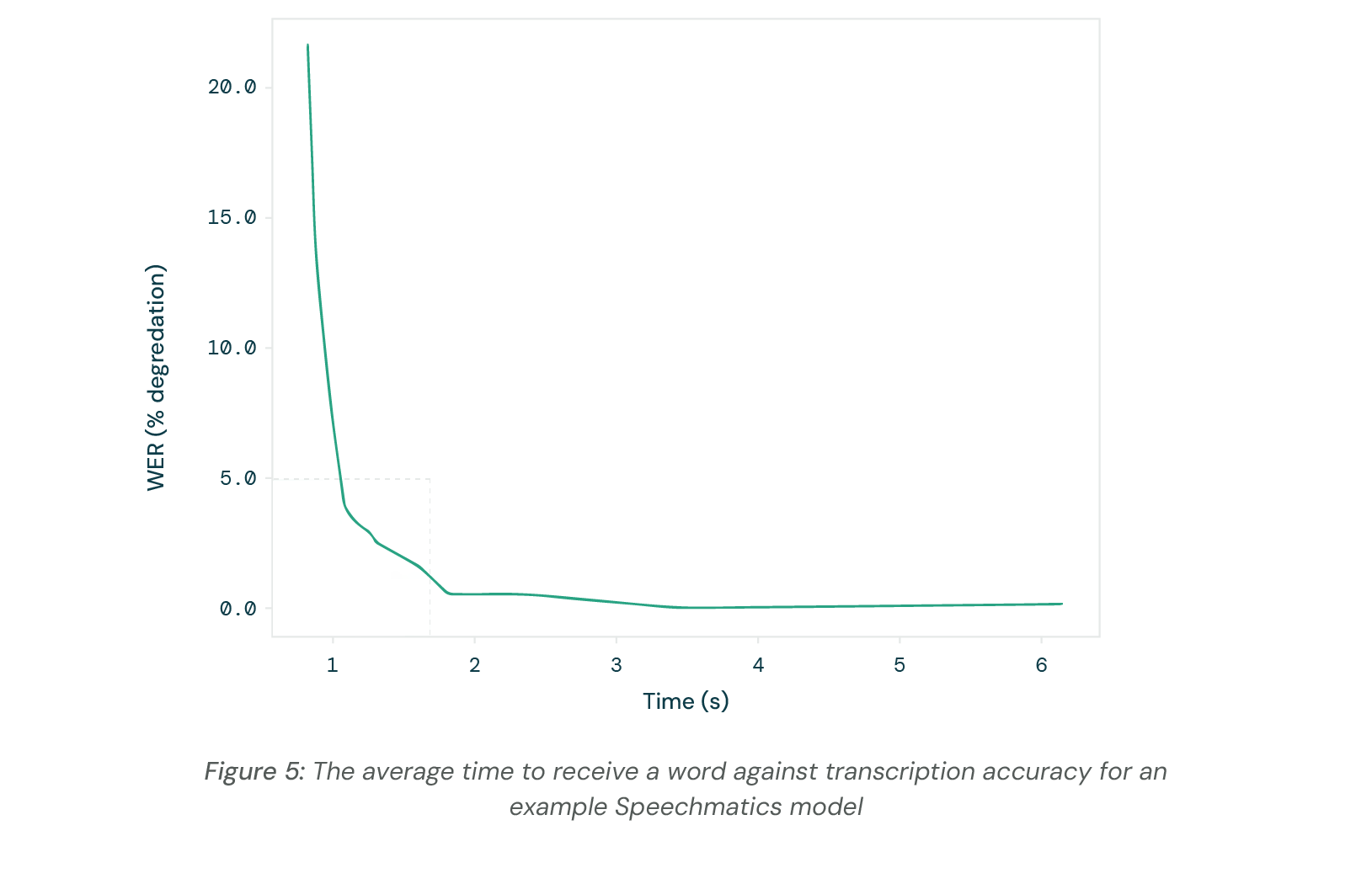
The figure shows that there is a clear trade-off between latency (x-axis) and accuracy (y-axis). This shows that as the amount of context given to a model reduces, the less well it can interpret speech. An ideal model would sit as far into the bottom left corner as possible, which would make it both low latency and high accuracy.
We mentioned earlier the difference between “infrastructure” and “information” delays. If we had only information delays, we would expect the error to go to 100% as the future context goes to 0s. However, the curve appears instead to asymptote to 0.25-0.5s latency. This is the offset caused by the infracture delays, and to get below this would require the model to return with negative future context, i.e. without having heard the words finish before returning them.
Above ~2s of latency there are not huge gains from further increasing the allotted future context, but below ~1s the accuracy quickly degrades.
To evaluate the potential for improving on this latency/accuracy trade-off, we tried training models specifically to deal well with a reduced future context. The curves for several such models are shown below in Figure 5, marked by the relative amount of future context offered to each.
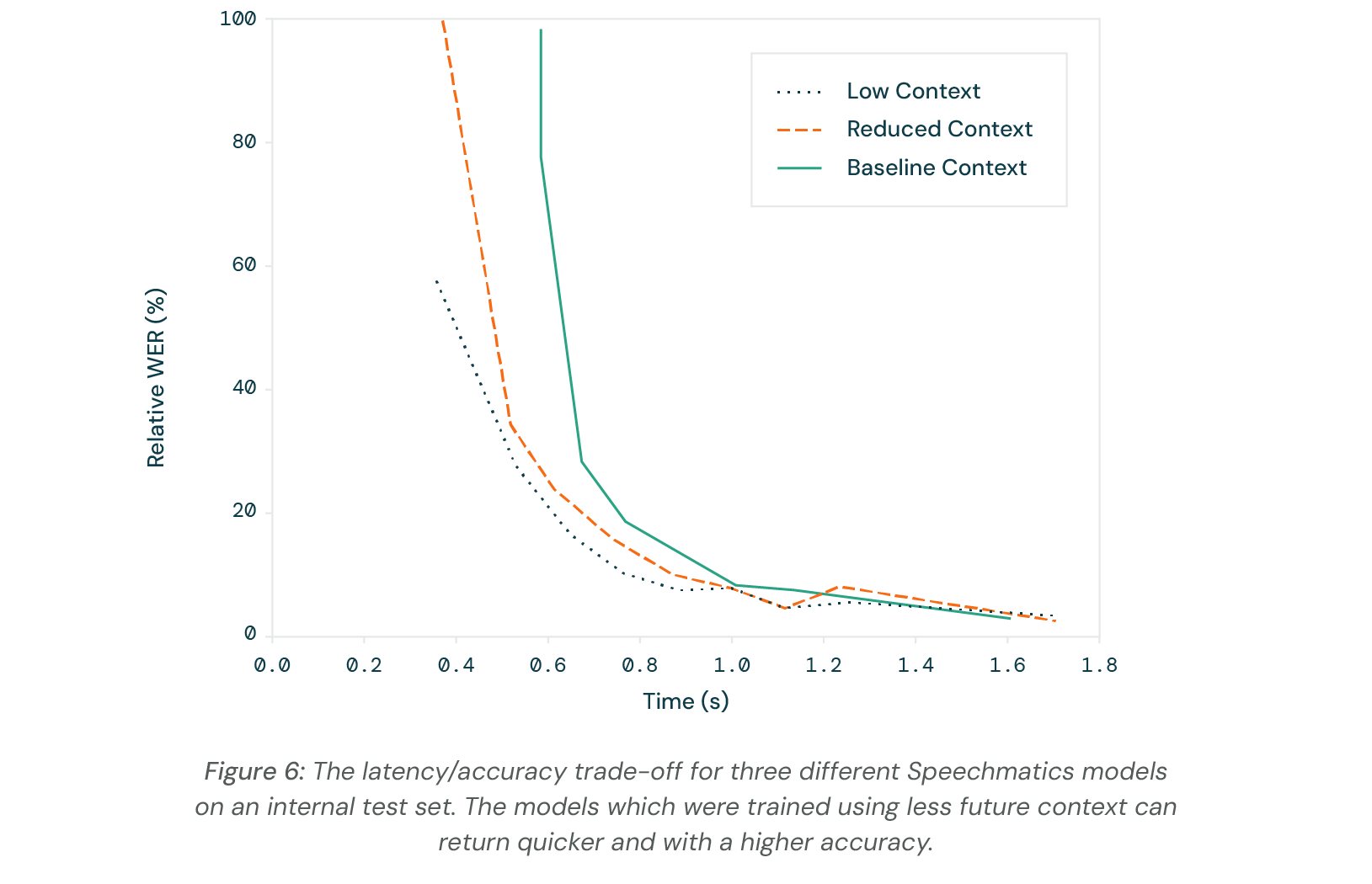
It is possible to train models specifically to work better at a specific part of the operating region. By pulling the curve further into the latency/accuracy corner, we are showing models which are even more accurate at lower latencies.
What this data shows is that as you try to return words in real time, there comes a latency below which it is very hard to maintain accuracy. For a given use case, the correct part of this trade-off should be chosen.
Competitor comparison
It is interesting to see how different ASR providers make the latency / accuracy trade-off. Figure 7 compares the real-time systems of several providers, as served by their SaaS endpoints. The “partials” and “finals” are displayed with different icons for each provider.
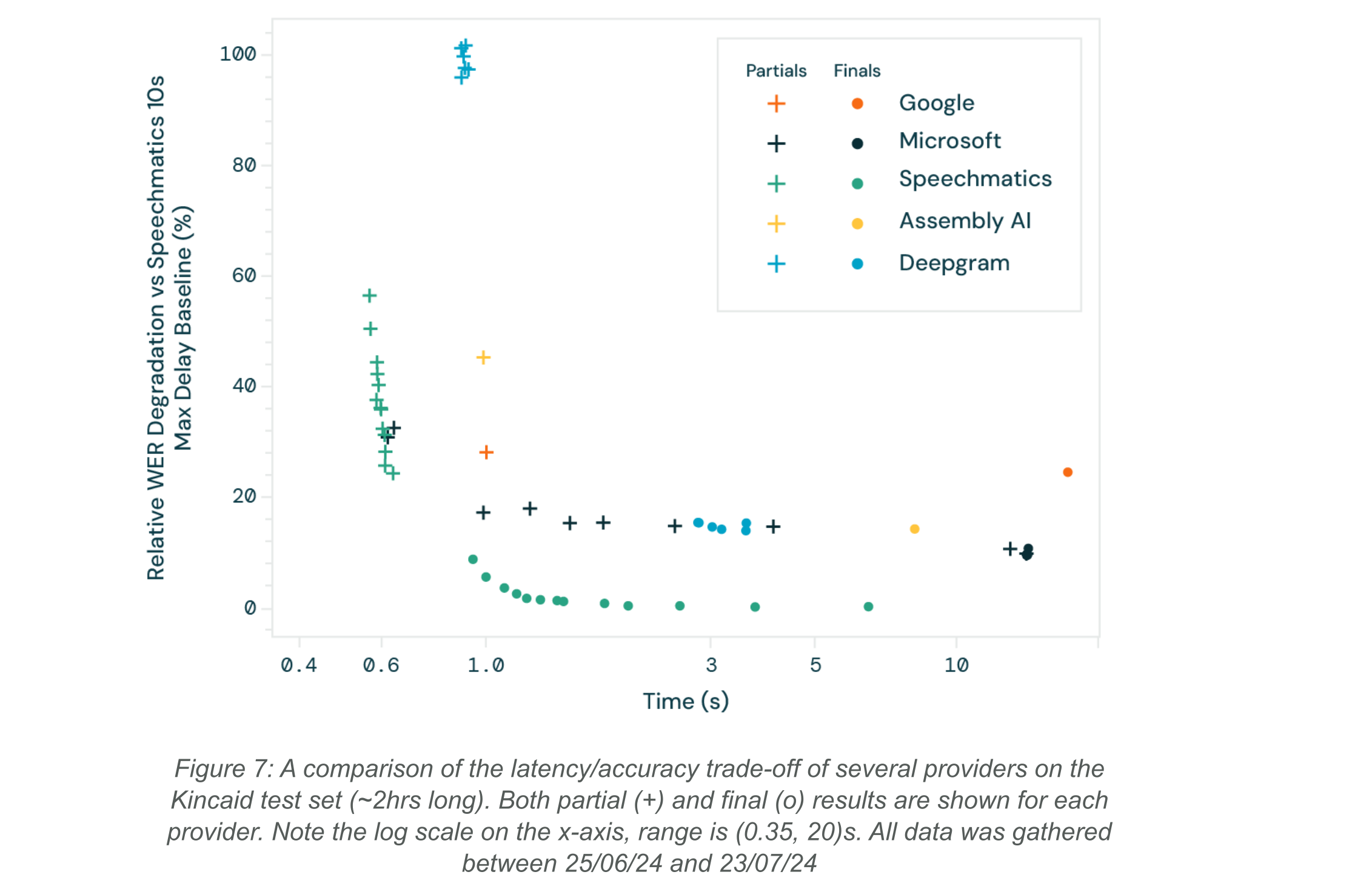
It can be seen that what is meant by “real time” has a wide variation. Many providers provide finals when there is a silence gap in the transcript, taking up to ~30s between finals (for an average time of ~15s). To provide a real-time element, the partials are returned to fill in the gaps.
Only Speechmatics and Microsoft offer a configuration parameter for the latency of the returned words. Microsoft use stable_partial_threshold and Speechmatics use max_delay. The shape of the latency/accuracy curves are similar between providers, being mostly flat until the latency gets below a few seconds. Under 1s the accuracy quickly degrades as the context goes to 0.
In general, the accuracy of partial results is much lower than those of finals. Speechmatics shows the best accuracy across all latencies for this testset, but especially <2s. This shows the advantage of models specifically tuned to return actionable results as fast as possible.
Looking forward
We have seen that there is a clear trade-off between the latency of an ASR system and the accuracy. We have also shown that it is possible to improve the trade-off which must be made, by training a system to be more accurate and require less informational context. But what comes next?
At Speechmatics, our first priority is to provide our customers with the models which give the best performance at their preferred latency. In our latest update, we halved the lowest finals latency achievable from 2s to 1s, with only a small reduction in accuracy.
However, as we push the boundaries to understand every voice, we will need to expand our model’s understanding of human speech. In a real-time conversational application, there are many non-verbalised information pathways to be incorporated, for example;
- signalling audibly and visually when you wish to start speaking,
- signalling understanding and agreement/disagreement,
- signalling audibly that you are approaching the end of your utterance and are ready for the other person to reply,
- signalling an interruption or an interjection.
Once these communication forms are incorporated, the latency of understanding can be optimised. If you know when the person is about to finish, you can then decode what they have said over the whole utterance in preparation for a reply or a reaction. Humans constantly update their understanding of previous speech sections as new information comes in.
The fine balance of human approaches can be seen in the effect of speaking on a laggy internet connection, when even a few hundred millisecond delay makes it much harder for a conversation to flow.
Tackling the nuance of conversation will be the next step in the human/computer interface, and at Speechmatics we hope to build this on our solid foundations of fast and accurate transcription.