
Speaker diarization often complements automatic speech recognition (ASR) by determining "Who spoke when?". One intriguing advancement in the field is the adoption of Self-Supervised Learning (SSL). By harnessing vast amounts of unlabelled audio data, SSL manages to improve multiple downstream tasks, including ASR and diarization, using the same pre-trained model. As we explore in this blog, the synergy between SSL and traditional methods not only boosts ASR accuracy but also aids in improving speaker diarization results.
Use Cases
Speaker diarization is often used alongside automatic speech recognition (ASR) to gain further insights into spoken data. It answers the question "Who spoke when?" by assigning a unique speaker ID to words and sentences.
There are several use cases for speaker diarization. One is to improve readability of transcribed text. Consider the example below:
That movie was amazing! Yeah, I was totally blown away. We should definitely watch it again. Agreed, it's one of the best I've seen.Speaker 1: "That movie was amazing!"
Speaker 2: "Yeah, I was totally blown away."
Speaker 3: "We should definitely watch it again."
Speaker 1: "Agreed, it's one of the best I've seen."
We can see that having a unique speaker label for each sentence in the transcribed text makes it easier to read. This is quite useful when producing subtitles for example. Based on the output we also get information about how many speakers are involved in the conversation.
The recent popularity of using LLMs such as ChatGPT to perform text analysis has brought new potential use cases for speaker diarization. The speaker labels can enable us to perform speaker level sentiment analysis ("how happy was the customer with product X?") or capture other meeting insights ("who raised questions about topic Y?").
Speaker Diarization vs Speaker Identification
Speaker diarization and speaker identification as terms are sometimes used interchangeably, even though there is a distinct difference between them.
Speaker diarization is the process of distinguishing and segmenting audio into sections based on the presence of different speakers. It assigns generic labels to these segments, like "speaker 1," "speaker 2," etc., without any prior knowledge of who these speakers might be. It's purely about discerning when one speaker's segment ends and another begins.
On the other hand, speaker identification is the process of determining the specific identity of the person speaking. This requires prior knowledge of the potential speakers in the audio set. In other words, it's about matching the voice in a given segment to a known individual.
Speaker identification can often be implemented using the same methods or systems as speaker diarization, but you would also a need a permanent database to hold information about different speakers and their acoustic characteristics. It's worth noting that speaker identification can be more straightforward than diarization. Given that speaker identification operates on the premise that the speaker models are already well-defined and stored, decisions regarding identity can be swiftly made upon analyzing a short segment of audio. In contrast, diarization, especially in real-time (RT), poses more challenges. It often necessitates examining multiple audio examples before confidently determining and separating the speakers.
Speaker Diarization Methods: Modular Approach vs End-to-end
There are two general architectures to implement speaker diarization in the context of ASR. One is the so called modular or cascade approach which is illustrated in the figure below.
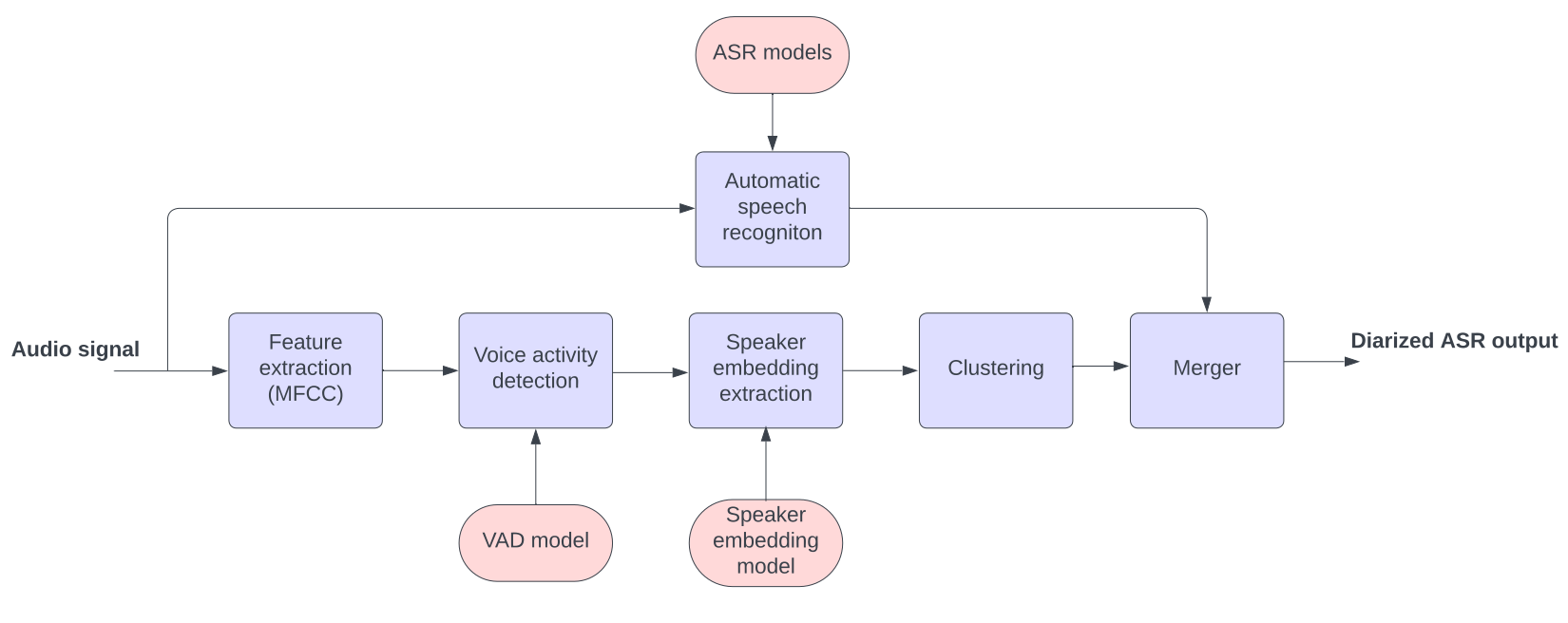
The main components of the modular diarization system are the following:
- Feature extraction: The first step is to extract relevant audio features from the input signal. Mel-frequency cepstral coefficients (MFCCs) are often used as input features for speaker diarization systems.
- Voice activity detection (VAD): VAD aims to determine the segments of the audio where speech is present, separating it from non-speech regions. VAD is an important step in diarization, because allowing non-speech through can introduce false speakers.
- Speaker embedding extraction: After VAD, the modular diarization system extracts speaker embeddings from the speech segments. It's important to understand that a single speech segment doesn't necessarily equate to a single speaker. Instead, within each VAD segment (or speech segment), overlapping windows are typically used to create a series of embeddings. This ensures a more granular and accurate representation, capturing potential variations or transitions between speakers within a segment. Speaker embeddings are compact representations that capture unique characteristics of individual speakers. These embeddings can be derived using techniques such as deep neural networks, which map the acoustic features of a speaker's speech to a fixed-dimensional vector of real numbers. Common training objectives for training a speaker embedding model are for example x-vector or contrastive loss. X-vector extracts speaker-specific features derived from training a speaker ID classifier (Snyder et al., 2018). Contrastive loss operates on pairs of embeddings (Radford et al., 2021). For each pair, the loss either tries to bring the embeddings closer if they belong to the same speaker or push them apart if they belong to different speakers.
- Clustering: Once the speaker embeddings are obtained, the clustering component groups them based on their similarity. Clustering algorithms aim to identify distinct speaker clusters in the diarization process. The embeddings of the same speaker should be closer to each other, while embeddings of different speakers should be further apart. For example cosine similarity can be used as a distance measure between speaker embedding vectors. Clustering often achieves optimal results when it has access to the embeddings across the entire audio file. However, due to challenges posed by large files or latency requirements, obtaining embeddings from the complete file may not always be feasible. In such situations, compromises might be necessary to ensure timely and effective clustering.
- Merger: The merger component is specific to diarization systems that are used alongside ASR. The purpose is to align the diarization result with the timestamped ASR output, so that a speaker is assigned to each recognised text segment.
The main advantage of the modular diarization system is its flexibility. You can easily re-train and swap out different components of the system. However, having many components can also lead to complexities in integrating the system. Also, each module in the system is optimized independently, focusing on its specific task, rather than optimizing on the diarization error rate (DER).
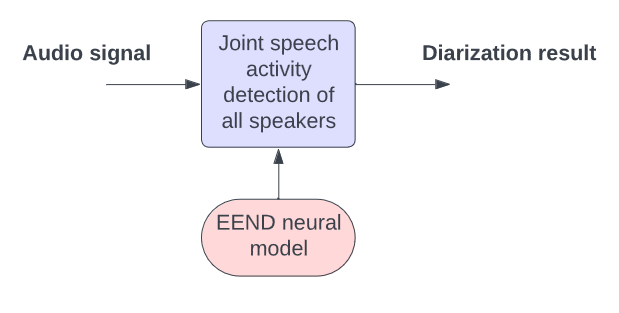
In recent years, end-to-end speaker diarization has become an alternative approach to implementing speaker diarization (Fujita et al., 2019). By leveraging the power of deep learning, end-to-end speaker diarization aims to overcome some of the limitations of the modular approach, including complex integration, inter-module dependencies, and lack of optimization across modules. In an ideal case (as illustrated in the figure below) you can have one neural network that is trained and optimized on the diarization error rate and can directly take an audio signal and output the diarization result.
Error Metrics
In ASR, the dominant error metric is word error rate (WER) which is used to measure the overall accuracy of a model or system. In speaker diarization, there are several metrics to evaluate the performance of a system. The most common error metric is the diarization error rate (DER). DER is calculated by summing up the missed speech (deletion), false alarm (insertion), and speaker error rates (substitution) and dividing it by the total duration of speech. It provides a comprehensive measure of how well a system can identify and attribute speech segments to individual speakers in an audio recording.
Despite its widespread use, DER is not always the best metric for every use case. When diarization is used alongside ASR, an alternative metric is the word diarization error rate (WDER). WDER is based on the same summation of deleted, inserted and substituted speaker IDs as DER, but takes into account the timings of the recognised words. Any speech segments that fall outside of the word timings are not taken into account when calculating WDER. The WDER metric is more aligned with what the end user sees when assessing the final diarized ASR output.
In the realm of speaker diarization, accurately segmenting audio into different speaker turns is as crucial as identifying the speakers themselves. This is where the segmentation F1 score comes into play, which is the harmonic mean of precision and recall.
To illustrate the importance of the segmentation F1 score, consider an example where one speaker dominates the conversation, speaking for 95% of the time, while a second speaker interjects frequently but with short contributions. If a diarization system simply recognized the entire audio file as being from the dominant speaker, the DER would report a seemingly acceptable 5% error rate. However, this doesn't capture the system's failure to recognize the second speaker's contributions. In this scenario, the segmentation analysis would reveal a 0% recall for the second speaker, highlighting a significant issue with the system's performance.
How Much Does Self-supervised Learning Help Speaker Diarization?
In other blogs we have talked about how Speechmatics leverages self-supervised learning (SSL) for ASR to improve sample efficiency. Self-supervised learning involves training deep neural networks on large amounts of unlabelled audio data by creating learning tasks from the data itself. The model learns to predict parts of the audio, such as missing segments or future samples, without needing manual transcriptions.
The output of the SSL model can be used as input features to our ASR model. We have found that leveraging hundreds of thousands of hours of unlabelled data improves the robustness of our ASR models to different accents and recording conditions. Reliance on labeled speech data, which is often a scarce resource, is also reduced.
Another benefit of SSL is that we can reuse the pre-trained models for other downstream tasks, or so called training heads. In Speechmatics, we use the same SSL models for both ASR and speaker diarization. The SSL or body features are used as input features (instead of MFCCs) when training the speaker embedding extractor.
| Feature type | Parameters | Unlabelled training data [h] | WDER [%] | SegF1 [%] |
|---|---|---|---|---|
| MFCC | - | - | 23.2 | 50.3 |
| SSL | 246M | 160k | 17.2 | 55.0 |
| SSL | 254M | 1.3M | 14.5 | 60.8 |
| SSL | 1.5B | 1.3M | 14.1 | 62.3 |
In the table above, we have results comparing the performance of our diarization system using MFCC and SSL-based input features. The results are reported in both WDER (lower value is better) and segmentation F1 score (higher value is better).
As we can see, we get a noticeable improvement in WDER (26-39% relative) on our internal test set when using SSL features as input to the speaker embedding extractor. The improvement of segmentation F1 score is also significant (9-24% relative).
Also looking at the table, it's evident that as we scale up the parameters and/or utilize more unlabelled training data, the performance in speaker diarization improves steadily. This suggests that further investments in larger SSL models and diverse unlabelled datasets could yield even more refined diarization results.
Future Research Directions
Speaker diarization, as well as ASR, has improved a lot in the last decade but it is not a "solved problem" by any measure. It's worth noting that diarization is a hard problem even for humans at times. In crowded or noisy environments, or during heated discussions where multiple people might speak at once, even our ears and brains can struggle to discern who is saying what.
Looking ahead, our focus will likely be on developing more sophisticated models that can better handle complexities, such as overlapping speech, noisy conditions and short interjections. End-to-end systems are probably well suited for tackling some of these problems.
Furthermore, we will continue to scale up our SSL models to improve performance of downstream tasks such as speaker diarization.
References
- David Snyder, Daniel Garcia-Romero, Gregory Sell, Daniel Povey, and Sanjeev Khudanpur, 2018. X-vectors: Robust DNN Embeddings for Speaker Recognition.
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever, 2021. Learning Transferable Visual Models From Natural Language Supervision.
- Yusuke Fujita, Naoyuki Kanda, Shota Horiguchi, Yawen Xue, Kenji Nagamatsu, and Shinji Watanabe, 2019. End-to-end Neural Speaker Diarization with Self-attention.