
When talking to a voice AI, few things are as frustrating as getting interrupted just because you paused for a moment to think. As humans, we naturally pick up on a wide range of cues to know when someone is done speaking — body language, tone, context, even the subtle shifts in breathing.
But for a machine, this is a much tougher problem. Simply waiting for a fixed 500ms of silence isn't enough, and it's a quick way to drive users away.
This post is about making turn detection smarter. I'll walk you through why Semantic Turn Detection is a big upgrade over just listening for silence, how instruction-tuned Small Language Models (SLMs) fit the job perfectly, and share a practical code example using an open-source SLM to help you get started.
If you're building voice AI, this approach can reduce those annoying, premature interruptions, save on API costs, and make your voice agents feel a bit more human. Let's dive in.
Traditional approaches typically rely on Voice Activity Detection (VAD) to detect the end of an utterance, which listens for changes in sound patterns to identify speech boundaries. But here's the catch — VAD only understands audio patterns.
It knows when there's speech and when there isn't. What it doesn't know is why there's a pause. Is the person thinking? Looking something up? Or actually finished speaking? VAD doesn't know, and that's where the problems start.
For instance, consider this interaction:
Agent: "Could you please provide your 8 digit customer ID?"
Customer: "Sure it's 123 764… (pauses to check their notes)"
Agent (interrupting): "Sorry, I didn't catch that. Can you repeat your full customer ID?"
In this case, a VAD-based system mistakes the pause for the end of the turn and jumps in too early. But a human wouldn't just wait — they'd recognize the context. We know that people often pause to recall something or check their phone or notes. That understanding of why someone pauses gives humans the confidence to stay silent a bit longer. That's the kind of intelligence VAD alone can't offer.
Introducing Semantic Turn Detection
To fix this, we need more than just an ear for silence. We need a model that understands meaning. That's where language models come in.
Unlike traditional VAD models, modern day Large Language Models (LLMs) are trained on massive amounts of text data, including conversations. This broad exposure allows them to pick up on the subtle structures of human dialogue — not just when words are spoken, but why and how they're connected.

A Voice Agent pipeline with Semantic Turn Detection
You might be thinking: why not just use a frontier LLM and prompt it to act as a turn detector? Technically, you could — but in practice, that breaks down fast. Voice AI is extremely sensitive to latency. If your voice-to-voice interaction takes more than a second, it starts to feel robotic. And the reality is, between STT, LLM, and TTS, most if not all of your latency budget is already accounted for.
So we can't afford to blow another 500ms calling an API just to figure out if the user is done speaking. That's why using a Small Language Model (SLM) for this task makes way more sense. SLMs typically have fewer than 10 billion parameters, making them faster and more efficient than their larger LLM counterparts, while still providing enough semantic awareness to detect end of thought without tanking your response times.
There's also a cost angle here. If your voice agent's "brain" is powered by an LLM, especially one hosted by an external provider, unnecessary interruptions can quickly rack up expenses. Every time your voice agent cuts in too soon, it triggers an LLM API call, generating a response that often ends up being discarded when the user corrects or clarifies their input.
And when that happens, you're essentially paying twice: once for the premature response and again for the follow-up, all because the agent misread a pause.
By introducing semantic understanding into turn detection, you avoid this waste. Your agent knows when to listen and when to speak, just like a good conversational partner.
Intuition behind using a Small Language Model
Before jumping into exactly how to use an SLM for turn detection, let's clarify that when we refer to an SLM here, we're specifically talking about an instruction-tuned model, not just a base model trained purely on raw text. This distinction matters because instruction-tuned models are designed to follow explicit conversational instructions, making them particularly suitable for the turn detection task.
Now, let's first get a clear picture of how a language model "sees" conversations.
While we typically think of conversations as clear back-and-forth exchanges between a user and an assistant, an LM actually perceives the conversation as just one continuous stream of tokens. Each token corresponds to a unique ID that comes from the vocabulary the LM was trained on.
Here's an example:
User: Hello
Assistant: How may I help you today?
User: Can I have two chicken McNuggets and
From the LM's perspective, this conversation looks like this in ChatML format:

Notice the special tokens: <|im_start|>, <|im_end|>, and <|im_sep|>. These aren't just random — they explicitly mark the structure of the conversation. <|im_start|> and <|im_end|> indicate where a message begins and ends, while <|im_sep|> separates the role (user or assistant) from the actual message.
The SLM's primary job is predicting what token comes next. It sees the conversation token by token and tries to guess the most likely next token. This is what we normally call auto-regressive generation, because each predicted token is fed back as input to predict the subsequent one.
Normally, we just pick the next token with the highest probability as the model's output. But to detect an end of turn, instead of simply taking the highest probability token, we specifically check how likely the next token is to be <|im_end|>.
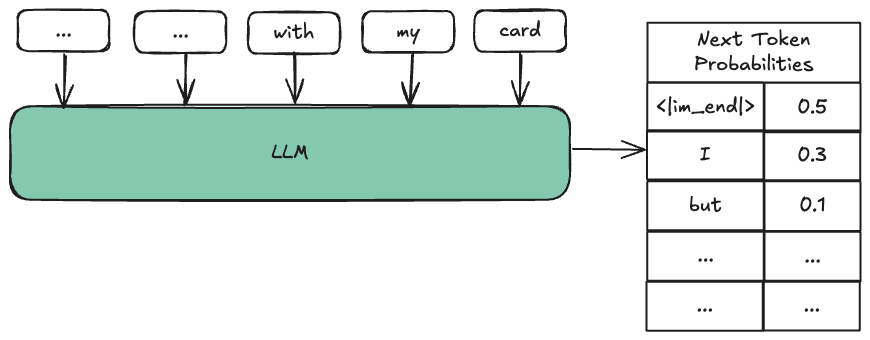
Looking at probabilities of first output token to determine end of turn
Why? Well, if the probability of <|im_end|> is high, that's a strong signal the user has finished speaking and it's now the assistant's turn. For example, in the phrase:
<|im_start|>user<|im_sep|>Can I have two chicken McNuggets and
We expect the probability of the next token being <|im_end|> to be relatively low because the user probably hasn't finished ordering yet. However, in:
<|im_start|>user<|im_sep|>I have a problem with my card
We expect a higher probability of the next token being <|im_end|> since this is likely a complete thought.
By analyzing the probability of <|im_end|> in the first output token right after the user's input, we effectively use the SLM as a semantic signal for detecting an end of turn.
And that's the intuition behind leveraging an instruction-tuned SLM for Semantic Turn Detection!
Implementing SLM-based Semantic Turn Detection
Want to skip to a fully working demo? Check out the full implementation on Github.
Alright, let's walk through how to actually implement turn detection using a language model. This part is where we connect the intuition from earlier to some practical code.
Note: We'll be using the instruction-tuned SmolLM2-360M-Instruct model from Hugging Face. Designed for efficiency, this compact model can run efficiently on CPU.
1. Tokenizing the Conversation
The first step is to tokenize the conversation in a format the model understands. For instruction-tuned models like the one we're using, this means formatting the conversation using ChatML. The code below sets up a simple Python class for this:
class EndOfTurnModel:
HF_MODEL_ID = "HuggingFaceTB/SmolLM2-360M-Instruct"
MAX_HISTORY = 4 # Maximum number of messages to consider in history
DEFAULT_THRESHOLD = 0.03 # Default probability threshold for determining end of turn
def __init__(self, threshold: float = DEFAULT_THRESHOLD):
self.threshold = threshold
self.tokenizer = AutoTokenizer.from_pretrained(self.HF_MODEL_ID, truncation_side="left")
self.model = AutoModelForCausalLM.from_pretrained(self.HF_MODEL_ID)
self.model.to("cpu")
self.model.eval()
def _convert_messages_to_chatml(self, messages: list[dict[str, Any]]) -> str:
"""
Converts a list of messages into a single string in ChatML format.
The EOT token (<|im_end|>) is removed from the last utterance, as the model
is expected to predict its presence.
Args:
messages (list[dict[str, Any]]): A list of message dictionaries, each with "role" and "content".
Returns:
str: A string representing the conversation in ChatML format.
"""
if not messages:
return ""
# Apply the chat template to format messages (e.g., adding special tokens like <|im_start|>)
tokenized_convo = self.tokenizer.apply_chat_template(
messages,
add_generation_prompt=False,
add_special_tokens=False,
tokenize=False,
)
# Important: Remove the end-of-turn token from the very end of the latest utterance,
# as we want the model to predict this token.
eot_token = "<|im_end|>"
last_eot_index = tokenized_convo.rfind(eot_token)
if last_eot_index != -1:
text = tokenized_convo[:last_eot_index]
return text
return tokenized_convo
In this snippet, _convert_messages_to_chatml formats a list of messages as a single ChatML string, removing the <|im_end|> token from the final user message, since that's what we want the model to predict.
2. Making the LM inference
Once you've formatted the messages, you'll want to pass them to the model to get the next token's log probabilities:
def get_next_token_logprobs(self, prompt_text: str) -> dict[str, float]:
"""
Performs local inference to get log probabilities for the next token.
Args:
prompt_text (str): The formatted conversation text.
Returns:
dict[str, float]: Dictionary mapping tokens to their log probabilities.
"""
inputs = self.tokenizer(prompt_text, return_tensors="pt", add_special_tokens=False).to("cpu")
with torch.no_grad():
outputs = self.model(**inputs)
next_token_logits = outputs.logits[0, -1, :] # Batch size 1, last token position
log_softmax_probs = torch.nn.functional.log_softmax(next_token_logits, dim=-1)
k = 20 # Get top N logprobs (e.g., 20)
top_logprobs_vals, top_logprobs_ids = torch.topk(log_softmax_probs, k)
top_logprobs_dict = {} # dict of token -> logprob
for i in range(k):
token_id = top_logprobs_ids[i].item()
# Decode the token ID to its string representation
token_str = self.tokenizer.decode([token_id])
logprob_val = top_logprobs_vals[i].item()
top_logprobs_dict[token_str] = logprob_val
return top_logprobs_dict
This function directly queries the LM for the next token's logprobs using the formatted messages as input. It uses the model's final layer logits to compute the logprobs.
3. Extracting End-of-Turn Probabilities
Finally, you need to interpret these logprobs to detect if the user is likely done speaking:
def process_result(self, top_logprobs: dict[str, float], target_tokens: list[str] = ["<|im_end|>"]) -> tuple[float, str]:
"""
Processes the model's output to find the maximum probability
among specified target tokens (e.g., EOT markers, punctuation).
Args:
top_logprobs (dict[str, float]): Dictionary mapping tokens to their log probabilities.
target_tokens (list[str], optional): A list of tokens to look for.
Returns:
tuple[float, str]: A tuple containing the maximum probability found for any
target token, and the token itself. Returns (0.0, "") if
no target tokens are found.
"""
token_probs = {token: f"{math.exp(logprob):.4f}" for token, logprob in top_logprobs.items()}
max_prob = 0.0
best_token = ""
for token_str, logprob in top_logprobs.items():
# The tokenizer might add leading spaces to tokens, so strip them.
stripped_token = token_str.strip()
if stripped_token in target_tokens:
# Convert log probability back to probability (exp(logprob)).
prob = math.exp(logprob)
if prob > max_prob:
max_prob = prob
best_token = stripped_token
return max_prob, best_token
This function checks if any of the top predicted tokens match the <|im_end|> marker, converting their log probabilities to actual probabilities for easier interpretation.
4. Putting It All Together
Here's how you might use this in practice:
def predict_eot_prob(self, messages: list[dict[str, Any]]) -> float:
"""
Predicts the probability that the current turn is complete.
Args:
messages (list[dict[str, Any]]): The list of messages.
Returns:
float: The probability (0.0 to 1.0) that the turn is complete.
"""
# Consider only the most recent messages, up to MAX_HISTORY.
truncated_messages = messages[-self.MAX_HISTORY:]
# Convert messages to the ChatML string format required by the model.
text_input = self._convert_messages_to_chatml(truncated_messages)
print(f"EOT Input: '...{text_input}'")
# Get log probabilities for the next token
top_logprobs = self.get_next_token_logprobs(text_input)
# Process the result to extract the probability of an EOT-indicating token.
eot_prob, _ = self.process_result(top_logprobs)
print(f"EOT Probability: {eot_prob:.4f}")
return eot_prob
This method ties everything together, checking if the probability of an end-of-turn is high enough to conclude the user's input.
That's pretty much it! You should now have a complete End of Turn model that uses an off-the-shelf instruction-tuned SLM. The complete implementation can be found in the Github repo.
Practical Challenges and Optimizations
Token Selection for Detection
While the simplest approach is to only monitor the probability of the special <|im_end|> token, this might miss some natural conversational cues. Punctuation like periods (.), question marks (?), and exclamation points (!) can also signal the end of a thought and capture more contextually complete turns.
A hybrid approach that considers these tokens as well could improve accuracy, though it might also introduce noise depending on the context.
Combining Semantic Turn Detection with VAD
You can definitely use Semantic Turn Detection on its own, but it usually works best when paired with VAD. For example, if VAD picks up a pause but the SLM thinks the person is still mid-thought, you can stretch the "grace period" a bit to avoid cutting them off. You can even tweak this grace period based on the speaking speed of the user, making the whole experience feel a bit more personal.
While VAD provides high recall by reliably detecting when someone is speaking, Semantic Turn Detection is key for improving precision. It adds the context needed to avoid false positives, reducing unnecessary interruptions and creating a smoother conversation flow. Finding the right balance here would therefore take some real-world testing.
Determining the Threshold
I used a default threshold of 0.03 in the code example earlier, but that's really just a starting point. The optimal threshold depends on your specific SLM and can vary significantly between models. If you're combining with VAD, you'll want to prioritize precision to avoid unnecessary interruptions. The best approach is to build a representative test set and iteratively fine-tune the threshold for precision.
Extending to Multiple Languages
If your voice agent needs to support multiple languages, you'll want a multilingual SLM that can handle the varied grammar and conversational norms across different languages. This can mean choosing an SLM that has been trained on diverse, multilingual data.
Fine-Tuning for Better Accuracy
While a general SLM should have a solid grasp of conversational dynamics, fine-tuning on your own conversational data can further improve accuracy. This step can be valuable if your use case involves specialized language or industry-specific terminology.
Wrapping Up: Where We're Headed Next
This is just the beginning. While combining Semantic Turn Detection with VAD can improve things, it still misses the subtle nuances of human speech. True conversational understanding requires more than just reading text or listening for gaps — it needs an audio-native model that can pick up on tone, cadence, and implicit cues like hesitation and emphasis.
Humans do this naturally, blending grammar, pacing, and intonation to sense when it's their turn to speak. Building systems that mirror this level of understanding is the next frontier in voice AI.